Jednym z dylematów, przed którym staje badacz, to problem doboru jednostek do badania. Jest to szczególnie istotne w przypadku badań sondażowych, w których wykorzystujemy próby losowe, które dają możliwość wnioskowania statystycznego z odpowiednią pewnością na całą populację. Dobór próby jest jednym z najtrudniejszych zadań na etapie realizacji badań, ale nie oznacza to, że jesteśmy całkowicie pozbawieni szans na poprawny dobór (zgodnie z zasadami metody reprezentacyjnej) i tym samym na poprawne analizy. Dobór próby może być skomplikowany, gdy nasza grupa docelowa jest bardzo liczna i wewnętrznie zróżnicowana.
Chcesz dowiedzieć się więcej o losowaniu prób?
Zapraszamy na szkolenie AN 3. Losowanie prób, ważenie, analiza braków danych
Rodzaje doboru próby
Badacze wyróżniają dwa typy doboru próby: metody doboru nieprobabilistycznego (nielosowego) oraz metody doboru probabilistycznego (losowego). Metody należące do doboru nielosowego, tj. dobór oparty na dostępności respondentów, dobór kwotowy, dobór celowy oraz dobór metodą „kuli śnieżnej”, wykorzystywane są przede wszystkim w badaniach jakościowych (wywiady indywidualne, grupowe), które tutaj nie będą omawiane.
Probabilistyczny (losowy) dobór próby pozwala na wnioskowanie o całej populacji z odpowiednimi błędami. Do tego rodzaju doboru próby zaliczamy: prosty dobór losowy, dobór losowy systematyczny, dobór losowy warstwowy oraz dobór losowy grupowy (zespołowy) oraz różnego rodzaju „hybrydy”, dobory złożone (warstwowo-zespołowe, wieloetapowe).
Doborem prostym losowym nazywamy taki sposób doboru jednostek, w którym przypadek losowy decyduje o tym, która jednostka zostanie dobrana z listy badanej populacji, a więc wszystkie jednostki mogą się znaleźć w próbie z tym samym, znanym prawdopodobieństwem.
Dobór próby krok po kroku
Proces doboru jednostek musi być poprzedzony zdefiniowaniem populacji, która będzie podlegać badaniu. Populacja rozumiana jest jako zbiorowość składająca się z elementów posiadających pewne cechy wspólne, które stanowią przedmiot zainteresowania badacza w kontekście wybranego wcześniej problemu badawczego. Warunkiem koniecznym, w przypadku doboru probabilistycznego jest zdobycie operatu – spisu jednostek należących do badanej populacji. W przypadku kiedy losowaniu podlegają jednostki, podstawą losowania mogą być np. książki telefoniczne, książki adresowe czy baza zawierająca numery PESEL. Od jakości operatu losowania zależy jakość wylosowanej próby. Czasami, pomimo prawidłowo przeprowadzonej procedury losowania, wyniki nie będą trafne, jeśli operat, którym dysponuje badacz okaże się niekompletny bądź będzie zawierał jedynie grupę osób o określonych cechach, determinujących stronniczość późniejszych odpowiedzi. W kolejnym kroku musimy ustalić, jaka liczebność próby będzie satysfakcjonująca w przypadku danego badania. Naszym celem jest bowiem możliwość generalizacji wyników na całą zbiorowość, z zachowaniem określonej wiarygodności i dokładności. Liczebność próby jest zwykle mocno związana z ograniczeniami finansowymi, jakim podlega badanie. Należy jednak zwrócić szczególną uwagę na ten aspekt doboru próby, zwłaszcza w przypadku, gdy badana grupa jest bardzo heterogeniczna.
Jak to zrobić w PS IMAGO PRO?
Do wylosowania próby badawczej wykorzystamy rozwiązanie PS IMAGO PRO, które oferuje wiele możliwości w tym zakresie. Skupimy się na dwóch sposobach: losowaniu prostym oraz losowaniu warstwowym. Pierwszy sposób, zwany inaczej indywidualnym losowaniem nieograniczonym, polega na losowaniu pojedynczych elementów zbioru, w którym każdy z nich ma takie samo prawdopodobieństwo znalezienia się w próbie. Losowanie proste stosuje się przede wszystkim wtedy, kiedy wiedza na temat populacji jest ograniczona, nie znamy jej struktury ani cech poszczególnych jednostek, przez co w porównaniu do innych metod (losowania warstwowego) daje niższą efektywność wyników. Warto dodać, że losowanie proste, dzięki takiemu samemu prawdopodobieństwu trafienia do próby dla każdej jednostki, sprawia że próba jest automatycznie ważona (samoważąca), co oznacza, że nie ma potrzeby uwzględniania dodatkowych wag w celu korekty różnych szans znalezienia się w próbie.
Losowanie proste zostanie zastosowane na danych, które odnoszą się do turystów odwiedzających polskie parki narodowe. W zbiorze mamy kilka istotnych informacji o potencjalnych respondentach. Wiemy, jaki park narodowy odwiedzili, ile mają lat oraz z jak dużej miejscowości pochodzą. W zależności od tego, jaki jest cel naszego badania, te informacje mogą być przydatne dla wybranego rodzaju losowania.
Załóżmy jednak, że jedyne informacje, jakie posiadamy to dane kontaktowe respondenta oraz jego id. W takiej sytuacji nie mamy zbyt wielkiego wyboru, jeżeli chodzi o sposób losowania. Możemy zastosować dobór prosty lub systematyczny. Oba te sposoby są dostępne w IBM SPSS Statistics, czyli silniku analitycznym rozwiązania PS IMAGO PRO. Dzięki temu nie ma potrzeby stosowania niewygodnych (i czasochłonnych) w użyciu tablic liczb losowych. W pierwszym rozważanym przypadku, zastosujemy technikę losowania prostego bez zwracania.
IBM SPSS Statistics/PS IMAGO PRO za pomocą funkcjonalności Próby złożone dostępnej w menu Analiza, umożliwia tworzenie planów losowania, losowanie prób oraz obliczanie statystyk z uwzględnieniem planów losowania. W przypadku, kiedy posiadamy dane odnoszące się do całej populacji i naszym celem jest wylosowanie próby, w kolejnym kroku należy wybrać opcję Wybór próby. Jeżeli natomiast pracujemy na pliku z danymi, które zostały uzyskane od wylosowanych wcześniej osób, a w analizie chcemy wziąć pod uwagę sposób, w jaki te jednostki zostały włączone do próby, należy wybrać opcję Przygotowanie analizy.
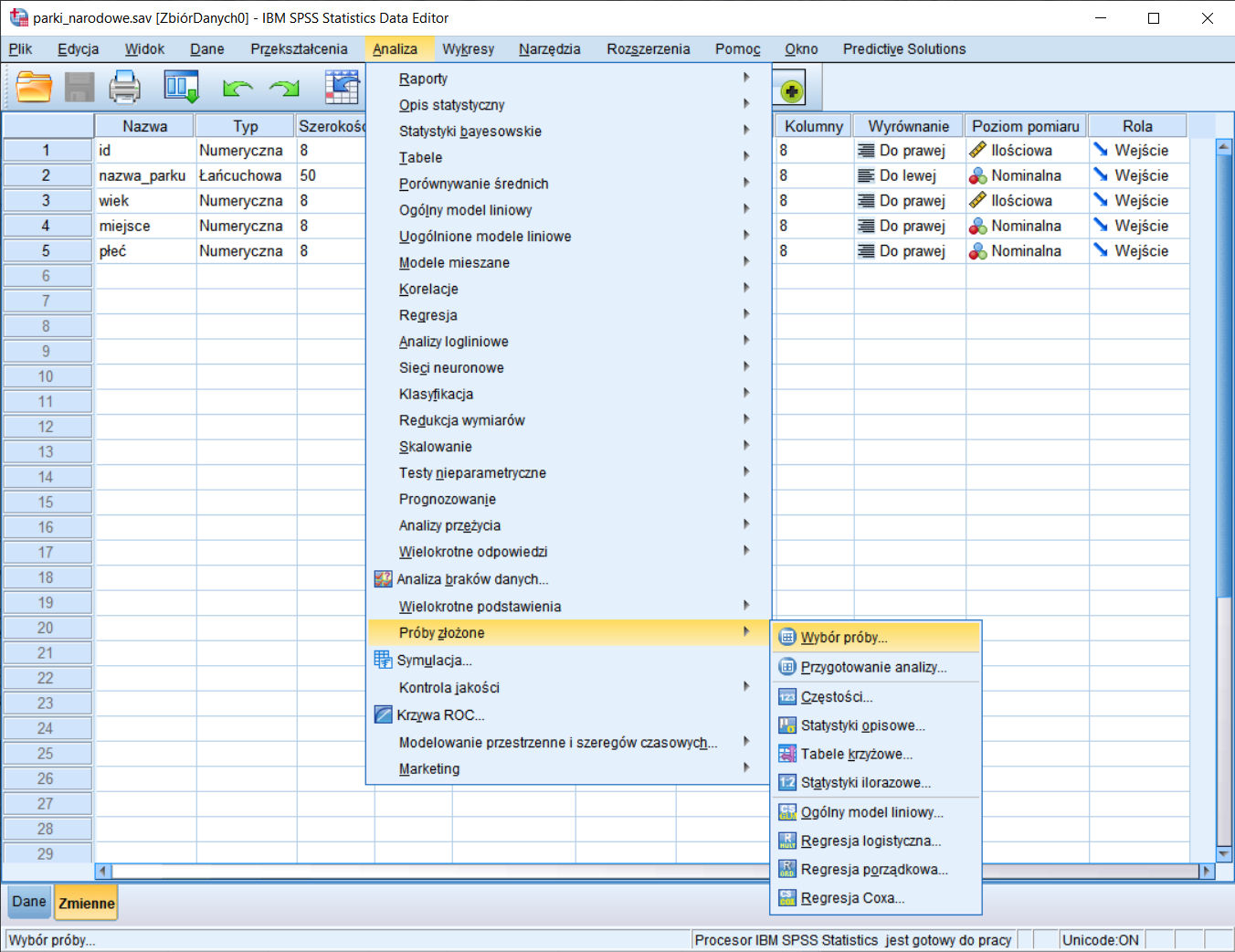
Rysunek 1. Krok pierwszy – wybór próby
Po wybraniu interesującej nas opcji, należy wskazać miejsce, gdzie program zapisze plik planu losowania, który musimy utworzyć, aby losowanie doszło do skutku. Jeśli dysponujemy już plikiem planu losowania, w tej części kreatora losowania prób możemy go edytować lub zaznaczyć, że na jego podstawie chcemy dokonać losowania.

Rysunek 2. Krok drugi – stworzenie pliku planu losowania
Kolejne okno kreatora pozwala nam na wybór zmiennych, które będą stanowić podstawę losowania warstwowego lub zespołowego oraz umożliwia określenie wejściowych wag próby. W przypadku losowania prostego, te opcje nie są nam potrzebne, więc po prostu przejdźmy do kolejnego okna, poprzez wybranie opcji Następny.

Rysunek 3. Krok trzeci – wybranie zmiennych planu
W kolejnym kroku należy wybrać metodę losowania, którą uznajemy za odpowiednią dla naszego typu danych. Program IBM SPSS Statistics/PS IMAGO PRO umożliwia nam zmianę metody z losowania prostego na: proste systematyczne, proste sekwencyjne, proporcjonalne (PPS), proporcjonalne systematyczne i proporcjonalne sekwencyjne. W tym oknie możemy także określić, czy chcemy żeby było to losowanie ze zwracaniem obserwacji. Z racji tego, że w tym przykładzie zdecydowaliśmy się na wykorzystanie losowania prostego bez zwracania, nie musimy zmieniać opcji domyślnie ustawionych w programie.

Rysunek 4. Krok czwarty – określenie metody losowania
Następne okno to możliwość określenia wielkości naszej próby. W poniższym przykładzie stała wartość wielkości próby została ustalona na poziomie 1000. Program pozwala nam jednak także na wykorzystanie proporcji (np. wybranie 10% wszystkich obserwacji z operatu).

Rysunek 5. Krok piąty – wyznaczenie wielkości próby
W kolejnym kroku, wybieramy te zmienne, które program ma zapisać po wylosowaniu próby. Możemy zdecydować się na zmienne odnoszące się do: wielkości populacji, rozmiaru próby, proporcji próby oraz wagi próby. W zależności od potrzeb informacyjnych zaznaczamy te opcje, które uznajemy za użyteczne. Jednak zaletą programu jest to, że niezależnie od tego, co będziemy chcieli dodatkowo otrzymać, zapisywane są nowe zmienne, które prezentują „prawdopodobieństwo włączenia” oraz „wagę próby” jako odwrotność prawdopodobieństwa. Przykładowo, gdyby nasza populacja liczyła 100 tys. jednostek, a chcemy wylosować do badania 1000 jednostek, to utworzona zostanie nowa zmienna, która powstaje przez wyliczenie 1000/100000. Inaczej to prawdopodobieństwo wyniosło 0,01, a jego odwrotność, czyli 1/0,01 daje nam wynik 100. Oznacza to, że jedna osoba z próby „reprezentuje” 100 osób w populacji. Włączając potem wagi w analizach, uzyskujemy wyniki przeszacowane na populację.

Rysunek 6. Krok szósty – zapisanie zmiennych wynikowych
Rysunek 6. Krok szósty – zapisanie zmiennych wynikowych
W następnym oknie otrzymujemy podsumowanie dotyczące podjętych przez nas decyzji oraz możliwość dodania kolejnego etapu losowania. Warto także zaznaczyć, że po wykryciu błędu, w każdej chwili możemy wrócić do poprzednich okien i zmienić dowolny element planu losowania.

Rysunek 7. Krok siódmy – podsumowanie planu
Zgodnie z zaznaczoną domyślnie funkcją, program sam wybiera liczbę startową, która stanowi punkt wyjściowy dla obserwacji wybranych na drodze losowania. W oknie Opcje wyboru mamy jednak możliwość wpisania własnej wartości, której generator liczb pseudolosowych użyje jako startowej. Opcja ta przydaje się wtedy, kiedy ponawiamy losowanie i chcemy otrzymać w jego wyniku próbę o dokładnie takiej samej strukturze jak ta, która została wylosowana poprzednio.

Rysunek 8. Krok ósmy – opcje wyboru
Po określeniu punktu startowego dla naszego losowania, musimy jeszcze wpisać ścieżkę, z której program skorzysta w momencie zapisywania wylosowanych danych. W tym celu wybieramy opcję Zewnętrzny plik i wpisujemy dogodną lokalizację.
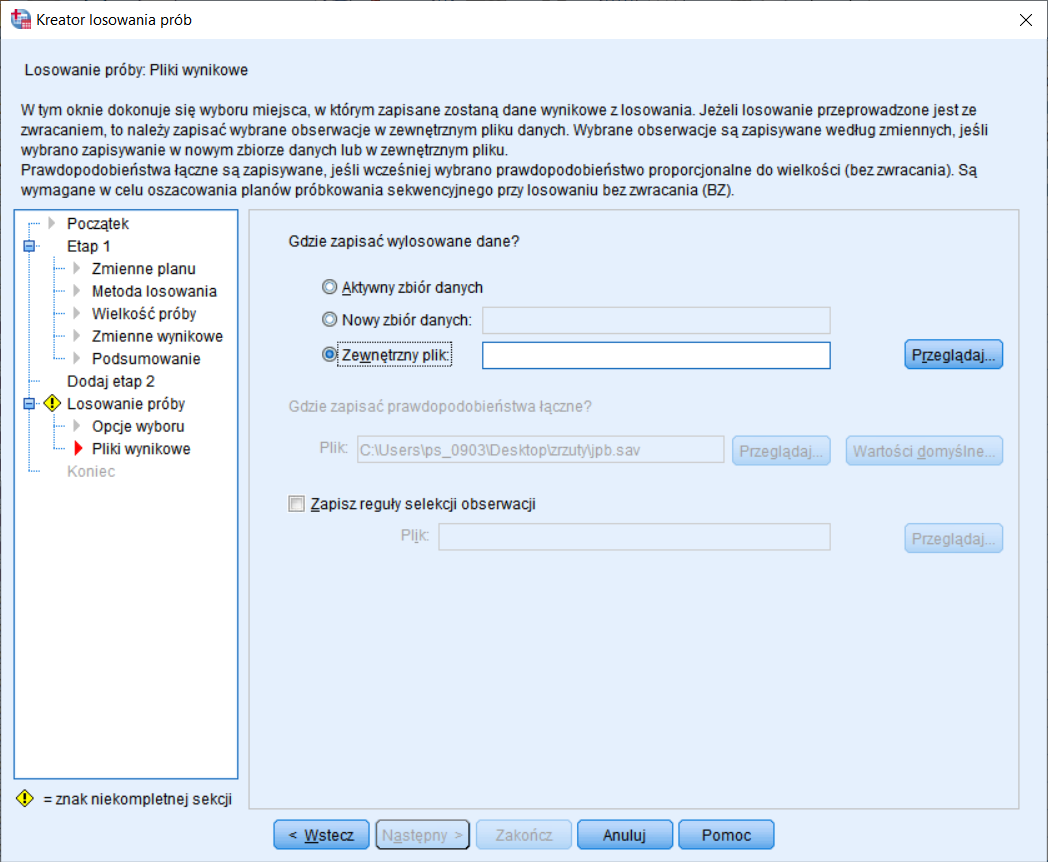
Rysunek 9. Krok dziewiąty – zapisanie danych uzyskanych na drodze losowania
W ostatnim kroku mamy możliwość wklejenia wygenerowanych komend do okna edytora komend. Jeśli jednak nie jesteśmy zainteresowani uzyskaniem polecenia, które stanowiło podstawę losowania, wybieramy opcję Zapisz projekt w pliku planu i wylosuj próbę.

Rysunek 10. Krok dziesiąty – wylosowanie próby
Po wybraniu opcji Zakończ, zgodnie z decyzjami, które podjęliśmy na etapie tworzenia planu losowania, zostanie wylosowania odpowiednia próba.
Losowanie warstwowe
Jeżeli dysponujemy wiedzą na temat heterogeniczności danej populacji, a operat zawiera informacje umożliwiające podział jednostek na podgrupy, wachlarz metod losowania rozszerza się. Jedną z możliwości, jaką daje nam rozwiązanie PS IMAGO PRO jest losowanie warstwowe, które polega na podziale całej populacji na tzw. warstwy i dokonaniu losowania niezależnych prób w obrębie każdej z nich. Podzbiory w operacie losowania tworzone są w ten sposób, aby jednostki były bardziej podobne do siebie w obrębie wydzielonego podzbioru, niż w stosunku do całej populacji. Każda jednostka musi być przypisana do jakiejś warstwy, ale nie może znajdować się w więcej niż 1 warstwie. Podzbiory te są rozłączne, ale razem tworzą populację. Homogeniczność podzbiorów jest kluczowa dla zwiększenia efektywności oszacowania parametrów rozkładu populacji. Im bardziej podobne do siebie, a zarazem różne od pozostałych warstw cechy jednostek, tym reprezentatywność próby większa względem losowania prostego. Przewagą losowania warstwowego w stosunku do prostego jest to, że pierwsze bierze pod uwagę cechy grupujące poszczególne jednostki, czego to drugie nie uwzględnia.
Korzystając z danych o liczbie turystów odwiedzających poszczególne parki, które generowane są przez Główny Urząd Statystyczny, możemy ustalić proporcje, które chcielibyśmy uwzględnić w planie losowania jednostek do badania turystów.

Rysunek 11. Ruch turystycznych w polskich parkach narodowych w 2010 roku (1. Źródło: Główny Urząd Statystyczny)
Aby rozszerzyć plan losowania o nowe informacje, należy ponownie przejść kroki opisane w przypadku losowania prostego. Na etapie wyboru zmiennych planu (krok trzeci), należy jednak przenieść zmienną, która zawiera dane na temat nazwy parku odwiedzonego przez turystę, do okienka zatytułowanego Warstwy według.

Rysunek 12. Wybranie zmiennych planu w przypadku losowania prostego warstwowego
Zdecydowaliśmy, że w losowaniu warstwowym chcemy bazować na proporcjach, które będą odzwierciedlały faktyczny ruch turystyczny w polskich parkach. Z tego powodu, w oknie pozwalającym określić wielkość próby, zaznaczmy opcję Nierówne wartości dla warstw.

Rysunek 13. Określenie wielkości próby w przypadku losowania prostego warstwowego
Po wybraniu opcji Nierówne wartości dla warstw wyświetli się okno, w którym będziemy mogli wpisać, ile jednostek ma zostać wylosowanych w obrębie wyznaczonych przez nas warstw, którymi są w tym przypadku polskie parki narodowe.

Rysunek 14. Określenie wielkości próby w obrębie poszczególnych warstw w przypadku losowania prostego warstwowego.
Pozostałe kroki, które należy przejść, aby doprowadzić do wylosowania próby są zbieżne z tymi, które stosowaliśmy w przypadku losowania prostego. Zachęcamy do samodzielnego sprawdzenia, jak z bazy turystów wylosować nie tylko próbę prostą, ale też próbę warstwową. Przykładowo, gdy założenie jest takie, że ogółem mamy dotrzeć do 1000 turystów, to z listy kontaktów osób pełnoletnich[i], które odwiedziły poszczególne parki i ich dane zostały zapisane w bazie możemy losować proporcjonalnie do udziału liczby turystów danego parku do liczby wszystkich turystów odwiedzających wszystkie parki narodowe w Polsce. Przykładowo, dla Kampinoskiego Parku Narodowego trzeba wpisać dla liczebności 189 osób do losowania, a w przypadku proporcji 0,189.
Analizy prezentowane w tym artykule zostały zrealizowane przy pomocy PS IMAGO PRO
[i] Trzeba dodać, że noworodki i dzieci także są wliczone w statystykę GUS jako turyści odwiedzający parki. Jednak jeśli wziąć pod uwagę, że jedynie z osobami pełnoletnimi założono przeprowadzenie badania, to warunek proporcjonalności nie jest „idealnie” spełniony, ale w prezentacji sposobu losowania warstwowego celowo został tak użyty.
Podsumowanie
Przedstawione w tym artykule opcje, jakie daje PS IMAGO PRO są zaledwie wstępem do wszystkich możliwości losowania, jakich możemy dokonać korzystając z tego kompleksowego rozwiązania analityczno-raportującego.
Wybór poszczególnych typów losowania czy metod określenia wielkości próby jest jednak ściśle uzależniony od postawionego przez nas problemu badawczego oraz struktury populacji, która stanowi przedmiot naszego badania.
Oceń artykuł:
[i] Trzeba dodać, że noworodki i dzieci także są wliczone w statystykę GUS jako turyści odwiedzający parki. Jednak jeśli wziąć pod uwagę, że jedynie z osobami pełnoletnimi założono przeprowadzenie badania, to warunek proporcjonalności nie jest „idealnie” spełniony, ale w prezentacji sposobu losowania warstwowego celowo został tak użyty.
