Jego twórcy mieli świadomość, że nie tworzą oprogramowania w próżni, a liczne i niedające się precyzyjnie określić potrzeby w przyszłości będą wymagać od platform data mining dużej elastyczności. Najlepszym tego przykładem jest:
- łatwość komunikacji z bazami danych przy pomocy SQL generowanego przez aplikację (a niekoniecznie hard-kodowanego przez człowieka),
- możliwość korzystania z dodatkowych algorytmów data mining (bibliotek napisanych np. w języku C), implementowanych przez użytkownika dzięki interfejsowi CEMI,
- wdrażanie procesów scoringowych w oderwaniu od środowiska aplikacji Clementine dzięki technologii Solution Publisher.
Dzisiaj o otwartości PS CLEMENTINE PRO (czyli następcy oprogramowania SPSS) najlepiej świadczą możliwości, jakie daje w kooperacji z R oraz Pythonem.
Python jako język skryptowy
Python w PS CLEMENTINE PRO współwystępuje ze starszą wersją języka skryptowego (tzw. legacy script, czyli w skrócie LS). Posiada przy tym znacznie większe możliwości interakcji z otoczeniem informatycznym, np. systemem operacyjnym, niż LS.
Wraz z instalacją dostarczana jest dedykowana biblioteka modeler.api, dzięki której możemy sterować obiektami w strumieniach i superwęzłach oraz tworzyć skrypty zarządzające wieloma strumieniami (skrypty sesji). Ktoś mógłby powiedzieć, że to tak samo, jak w przypadku korzystania z LS. Przyjrzyjmy się pierwszemu przykładowi, żeby zobrazować niektóre różnice.
Biblioteki Python w PS CLEMENTINE PRO
Jedną z cech Pythona jest możliwość wykorzystywania licznych bibliotek. Dla przykładu biblioteka Python os pozwala na dostęp do plików i folderów znajdujących się na dysku twardym komputera. Możemy więc z poziomu PS CLEMENTINE PRO nie tylko definiować ścieżki dostępu do plików (na co pozwalały już wcześniej LS), ale również tworzyć foldery, zbierać informacje o plikach, usuwać je czy zmieniać ich nazwy. Dodajmy do tego wykorzystanie modułu datetime i uzyskujemy narzędzie automatycznego zapisu raportów – raporty z każdego dnia znajdować się będą w osobnych, tworzonych automatycznie, folderach.
Ponadto PS CLEMENTINE PRO wspiera standardowe biblioteki Pythona, takich jak:
- Pandas: do manipulacji i analizy danych,
- NumPy: do obliczeń numerycznych,
- SciPy: do zaawansowanych obliczeń naukowych,
- Matplotlib i Seaborn: do wizualizacji danych.
Jak łatwo zauważyć, Python w PS CLEMENTINE PRO daje użytkownikowi bardzo dużo możliwości, które można również wykorzystać do automatyzacji procesów analitycznych.
Python w PS CLEMENTINE PRO – przykład automatyzacji generowanych raportów
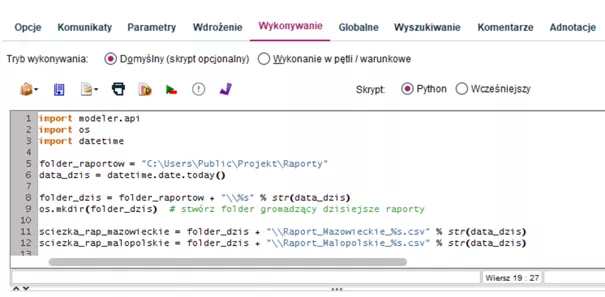
Poniżej znajduje się przykładowy fragment kodu służącego do utworzenia w folderze raportów projektowych podfolderu o nazwie będącej dzisiejszą datą (linie 1-9).
Rysunek 1.
Skrypt tworzący folder przy użyciu modułu os
W dalszej części (linie 11-12) tworzone są ścieżki dostępu do plików csv, które będą zawierały osobne raporty dla województw mazowieckiego i małopolskiego wraz z dzisiejszą datą w nazwie. Zakładając, że bieżący strumień generuje takie raporty osobnymi węzłami exportu (np. węzłami eksportu 'Plik płaski'), możemy automatycznie tworzyć ścieżki, które zostaną przez te węzły wykorzystane do zapisu plików.
Biblioteka Python os pozwala również na przeszukiwanie zawartości folderów w celu znalezienia pliku/folderu o określonej nazwie. W połączeniu z biblioteką re (obsługa wyrażeń regularnych) można dzięki temu np. wczytywać wszystkie pliki, których nazwy zawierają określony fragment: „raport”, „.csv” czy „2020-06”.
Korzystając z tych możliwości, należy pamiętać o uprawnieniach dla użytkowników do odpowiednich zasobów komputera. Brak odpowiednich uprawnień może powodować niepowodzenie wykonania zaplanowanego zadania.
Tworzenie własnych funkcji Python w PS CLEMENTINE PRO
Poza możliwościami korzystania z wielu stworzonych już bibliotek Python w PS CLEMENTINE PRO użytkownik ma również możliwość tworzenia własnych funkcji, upraszczających pracę. Przy bardziej skomplikowanych operacjach, pętlach czy instrukcjach warunkowych, takie podejście pozwala nie tylko na skrócenie czasu pracy, ale także na skrócenie samego kodu, poprawienie jego czytelności oraz uniknięcie pomyłek.
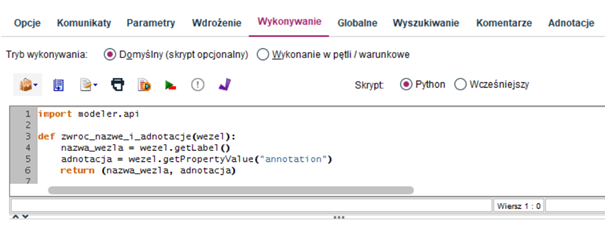
Rysunek 2.
Przykładowa własna funkcja Python
Przykładowa funkcja z rysunku powyżej „zwroc_nazwe_i_adnotacje” zwraca, jakżeby inaczej, nazwę i adnotację wybranego węzła. Możemy ją wykorzystać np. w celu dokumentacji operacji w strumieniu.
Zdefiniowaną funkcję można zapisać w pliku skryptu pythona (.py) lub pliku tekstowym i używać jej w przyszłości w innych skryptach. Nic nie stoi na przeszkodzie, aby utworzoną funkcję przesłać do innych członków zespołu, którzy również używają PS CLEMENTINE PRO. Co więcej, jeżeli stworzylibyśmy zestaw funkcji, który często jest wykorzystywany przez nasz zespół, Python umożliwia utworzenie pliku (nazwijmy go „nasza-bliblioteka”), który działałby analogicznie jak wykorzystywane wyżej biblioteki Python. Po odpowiedniej konfiguracji wystarczyłoby na początku dowolnego skryptu wprowadzić linię: „import nasza_biblioteka”, aby uzyskać dostęp do wszystkich zgromadzonych tam funkcji.
Zaawansowane algorytmy Python w PS CLEMENTINE PRO
Python w PS CLEMENTINE PRO jest wykorzystywany nie tylko w skryptach strumienia. Wykorzystują go również niektóre węzły. Znaleźć je możemy na palecie węzłów, w zakładce Python.

Rysunek 3.
Zakładka Python na palecie węzłów
Chodzi oczywiście o dodatkowe algorytmy i techniki analityczne. Znajdziemy tutaj m.in. zaawansowane modele uczenia maszynowego (Drzewo XGBoost, Las losowy, SVM, KDE), algorytmy przydatne do preprocessingu danych na potrzeby budowy innych modeli (SMOTE), jak i węzły umożliwiające import i eksport do formatu JSON. Wszystkie wykorzystują algorytmy napisane w języku Python. Tutaj warto pamiętać, że niektóre z nich wymagają instalacji określonych bibliotek zewnętrznych (np. imbalanced-learn dla SMOTE).
Rozszerzenia Python w PS CLEMENTINE PRO
Dla bardziej zaawansowanych użytkowników PS CLEMENTINE PRO ma jeszcze wyjątkowe funkcjonalności zawarte w węzłach rozszerzeń. Są to węzły, wewnątrz których możliwe jest wprowadzenie kodu w języku R lub w frameworku PySpark, czyli Pythonowym API, do Sparka – środowiska programistycznego do obliczeń rozproszonych. Wykorzystanie rozszerzeń Python w PS CLEMENTINE PRO może nam przyspieszyć oraz ułatwić automatyzacje procesów analitycznych.

Rysunek 4.
Węzły Rozszerzeń
Węzły te odpowiadają typom węzłów Clementine, zatem mamy tutaj węzły importu danych, przetwarzania rekordów i zmiennych, modelowania i eksportowania danych. Dzięki nim można m.in.:
- pobierać dane z adresu url (i innych źródeł obsługiwanych przez Pythona),
- wczytywać dowolną ilość plików na raz i elastycznie łączyć wewnątrz tego samego węzła,
- tworzyć zmienne w nowy sposób – wykorzystując funkcje PySpark,
- edytować dotychczasowe zmienne z wykorzystaniem funkcji Pythona,
- tworzyć i oceniać modele niedostępne w podstawowych węzłach Modelera,
- tworzyć własne wersje interfejsów algorytmów Python z opcjami, które uznamy za ważne,
- generować wyniki w formie tekstowej i wizualnej,
- formatować i eksportować dane np. do postaci plików JSON.
Wykorzystanie tych możliwości wymaga jednak przynajmniej podstawowej znajomości PySparka.
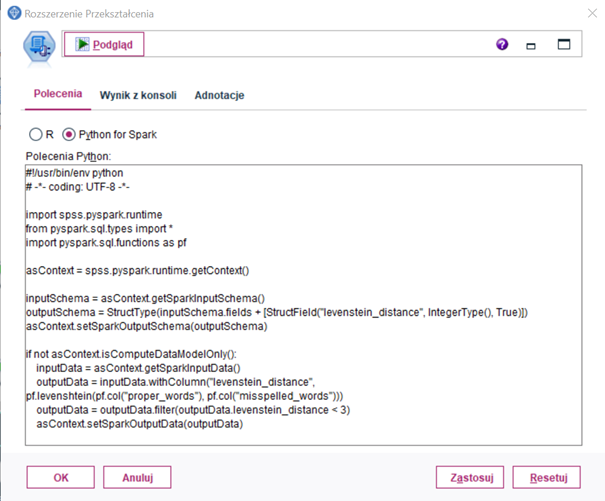
Rysunek 5.
Przykładowy kod we frameworku PySpark
Rysunek powyżej przedstawia przykładowo wypełniony węzeł Rozszerzenie Przekształcenia. Jego zadaniem jest dodanie do zbioru nowej zmiennej zawierającej odległość Levensteina (metryka dystansu pomiędzy dwoma ciągami znaków, której wartość wzrasta wraz ze wzrostem zmian koniecznych, aby z ciągu A, utworzyć ciąg B). W tym przykładzie dystans mierzony jest pomiędzy zmiennymi „proper_words” a „misspelled_words”. Dystans Levensteina to miara, którą możemy zaimplementować właśnie przy użyciu węzła Rozszerzeń. Dalej w kodzie, po policzeniu dystansu edycyjnego, selekcjonowane są te rekordy, gdzie odległość Levensteina jest mniejsza niż 3.
Rezultat działania tego węzła wygląda następująco:
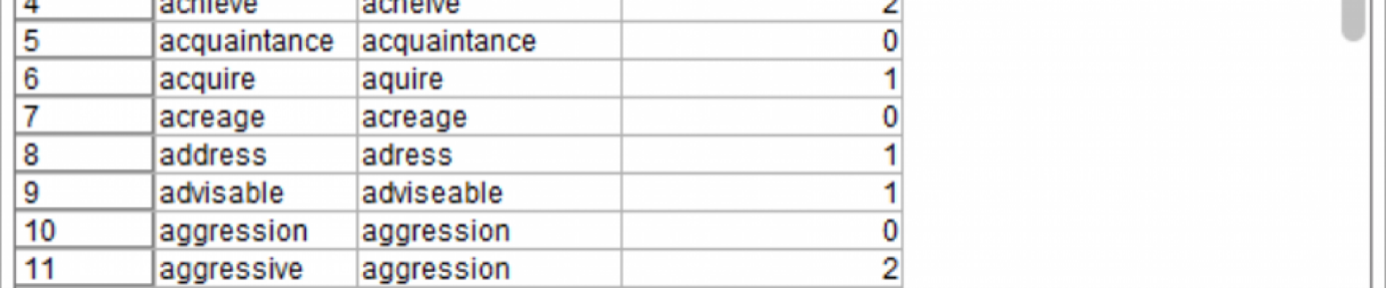
Rysunek 6.
Wynik z węzła Tabela zawierający wyliczoną odległość Levensteina
Węzły rozszerzeń Python w PS CLEMENTINE PRO umożliwiają wykorzystywanie różnych bibliotek. Nic nie stoi na przeszkodzie, by w strumieniu wykorzystać NumPy, Pandas, Matplotlib, Seaborn czy Scikit-learn. Daje to bardzo szerokie możliwości zarówno w kontekście modelowania danych, ich przetwarzania, jak i automatyzacji procesów analitycznych.
Przy użyciu węzła Rozszerzenie Przekształcenia można również wykorzystywać skomplikowane wyrażenia regularne przy pomocy modułu re. Te z kolei mogą wesprzeć analizy text miningowe, co jest oczywiście dość szerokim tematem i zasługuje na osobne omówienie.
Python w PS CLEMENTINE PRO – podsumowanie
PS CLEMENTINE PRO oferuje wiele możliwości integracji z językiem Python, co znacznie rozszerza jego elastyczność i funkcjonalność w zakresie data miningu i analizie danych. Python jest wykorzystywany zarówno w skryptach strumieni, jak i w zaawansowanych węzłach analitycznych. Dzięki temu użytkownicy mogą korzystać z popularnych bibliotek, takich jak Pandas, NumPy, czy Scikit-learn, oraz tworzyć własne funkcje dostosowane do specyficznych potrzeb.
Dostępne węzły Python umożliwiają implementację zaawansowanych algorytmów, takich jak XGBoost czy SMOTE, a także integrację z technologiami takimi jak PySpark. Węzły rozszerzeń pozwalają na elastyczne przetwarzanie danych, tworzenie modeli, przekształcanie zmiennych i eksport wyników w różnych formatach.
Dzięki zaawansowanym funkcjom i integracji z Pythonem, PS CLEMENTINE PRO staje się jeszcze bardziej wszechstronnym narzędziem do eksploracyjnej analizy danych i modelowania.