Nowoczesne środowisko analiz data mining i big data. Wielofunkcyjny interface ułatwia zarządzanie procesem i pracą grupową. To elastyczne rozwiązanie pozwala wykorzystywać zbierane już dane oraz łatwo integrować analizy predykcyjne z procesami biznesowymi organizacji. Szeroka paleta algorytmów predykcyjnych, w tym data science oraz machine learning pozwala na rozwiązywanie złożonych zagadnień. Wbudowana integracja z językiem Python dodatkowo zwiększa zakres możliwości.
Korzyści
Otwarte środowisko data mining, big data i data science
Kilkadziesiąt algorytmów IBM SPSS oraz w pełni zintegrowane technologie R, Python, Spark. Oznacza to dostęp do technologii sztucznej inteligencji w ramach jednego, nie wymagającego kodowania, interfejsu. Rozszerzenia R i Python pozwalają również efektywnie przetwarzać dane tekstowe, budować systemy oparte o usługi, czy korzystać z zewnętrznych silników graficznych.
Standard Data Mining
Silnik analityczny IBM SPSS Modeler to zaawansowane techniki modelowania oparte o procedury statystyczne oraz sztuczną inteligencję. Oferuje graficzną wizualizację wyników i integrację z innymi środowiskami analitycznymi oraz bazami danych.
Analizy w rękach użytkowników
Rozwiązanie ułatwia współpracę pomiędzy użytkownikami. Pozwala bezpieczne przechowywać procedury i pozostałe zasoby analityczne. Posiada opcję „one-click” - uruchamiania scoringów i innych procesów analitycznych również przez użytkowników biznesowych.
Łatwe zarządzanie procesami analitycznymi
Wbudowane funkcjonalności pozwalają na rozbudowane zarządzanie procesami analitycznymi - od tworzenia struktury, poprzez nadawanie uprawnień i blokowanie edycji, pracę grupową, aż po kontrolę procesu.
Oszczędność czasu obsługi procesów
Nowoczesna automatyzacja procesów obejmuje nie tylko uczenie modeli predykcyjnych, ale również rozbudowane typy automatycznego wyzwalania, powiadomienia o statusie wykonania czy historyzację uruchomień.
Elastyczne rozwiązanie
Architektura rozwiązania pozwala na elastyczne dostosowanie go do wymagań organizacji oraz integrację analiz predykcyjnych z procesami biznesowymi i systemami wewnętrznymi.
Rozwiązanie real time
Dystrybucja i wdrażanie wyników, ocen czy rekomendacji zapisywanych do baz danych może być realizowana w czasie rzeczywistym poprzez systemy operacyjne.
Komfortowy start
Korzystamy z technologii szeroko prezentowanych na najlepszych wyższych uczelniach na całym świecie. Użytkownicy otrzymują dostęp do biblioteki zasobów Predictive Solutions oraz IBM. Uzyskują pomoc od zespołu analityków z najdłuższym doświadczeniem pracy m.in. w technologiach IBM SPSS w Polsce – również w postaci szkoleń.
Dla kogo?

Data scientist
Zaawansowane analizy pozwalają mi wytypować klientów o wysokiej skłonności do przerwania współpracy.
Algorytmy PS CLEMENTINE PRO umożliwiają badanie zachowań klientów, oraz budowanie modeli analitycznych w celu wydobycia reguł zachowań prowadzących do odejścia klienta. Dzięki temu możemy przeprowadzić kampanie kierowanie do tych właśnie klientów, opierając komunikację o zjawiska, które uważamy za kluczowe do podjęcia decyzji przez klienta.

and data quality specialist
Ważne jest dla mnie ciągłe, najlepiej automatyczne monitorowanie jakości danych, weryfikacja ich przyrostów i sprawne raportowanie wyników.
Kontrola nad jakością danych jest nieodzownym elementem wszystkich procesów związanych z analizowaniem i przetwarzaniem danych. Bez tego niemożliwe jest podejmowanie trafnych decyzji. PS CLEMENTINE PRO wspiera procesy związane z integracją danych, monitorowaniem i poprawą jakości, a także umożliwia automatyzację tych zadań.

BI Data specialist
Budowa oraz automatyczne zasilenia analitycznych Data Martów wspierających optymalizację pracy.
PS CLEMENTINE PRO wspiera procesy związane z integracją i przetwarzaniem danych z różnych źródeł, więc świetnie sprawdza się do budowania dedykowanych analitycznie Data Martów oraz operacji ETL ich zasilania. Dzięki wbudowanej automatyzacji cykliczne zasilenia można zaplanować i przeprowadzić o najbardziej dogodnej porze. PS CLEMENTINE PRO pozwala również na przeprowadzanie zaawansowanych analiz w oparciu o utworzone Data Marty.

CRM Analyst
Najskuteczniejszy sposób zwiększenia wartości klientów i podniesienia średniego koszyka? Cross-selling, czyli polecanie dodatkowych produktów, w oparciu o analizę danych.
W działaniach sprzedażowych ważnie jest nie tylko zdobywanie nowych klientów, ale również budowanie trwałych relacji z aktualnymi i maksymalizacja płynącego z tych relacji zysku. Udaje nam się skutecznie zwiększać wartość klienta (LTV) dzięki kampaniom sprzedaży krzyżowej. Produkty do crosselingu dobierane są dzięki wykorzystaniu modeli predykcyjnych, które dostarczają informacji o poziomie prawdopodobieństwa zakupu danych produktów przez określonych klientów.
Możliwości PS CLEMENTINE PRO
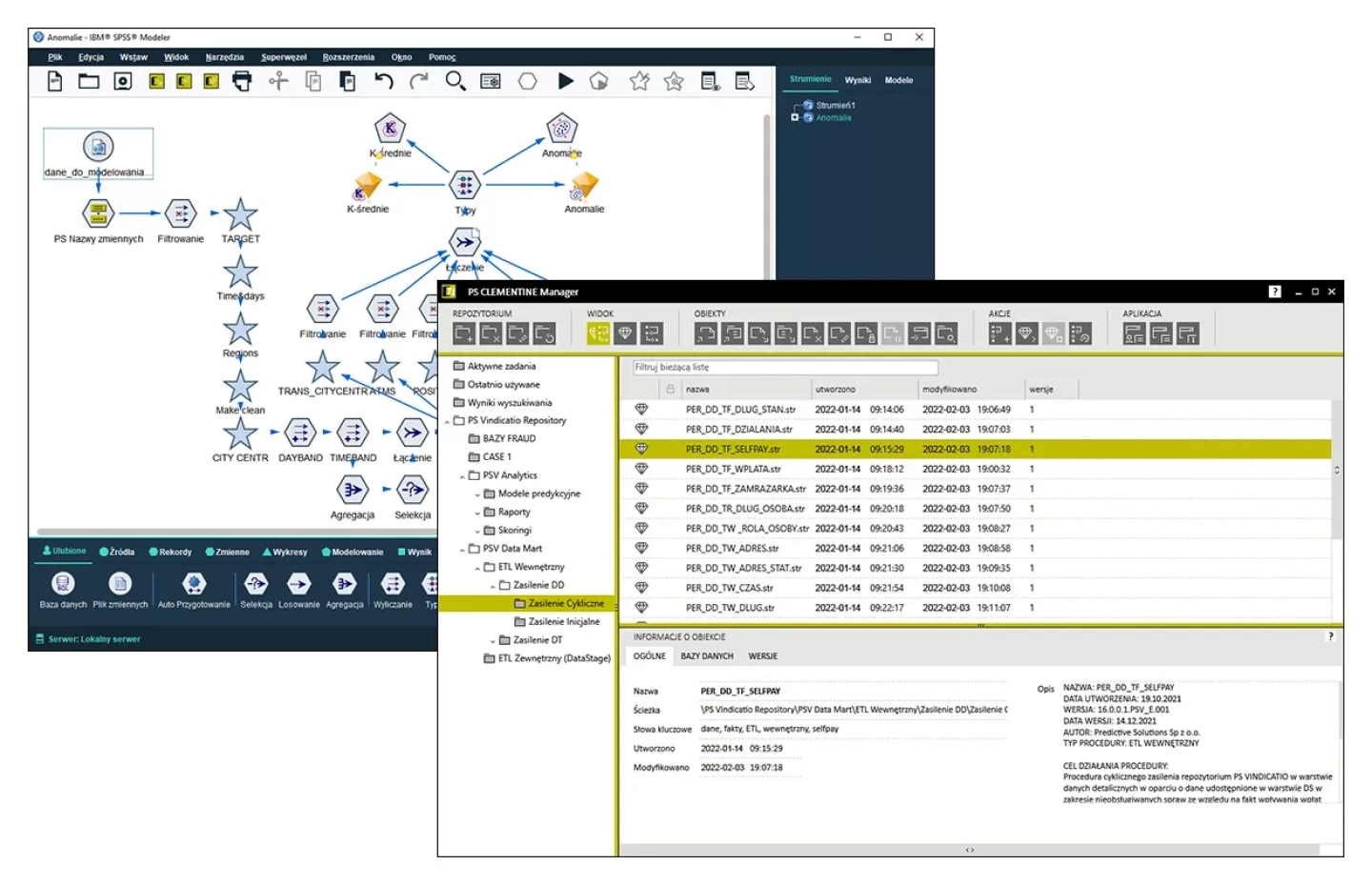
Szerokie możliwości analizowania danych i budowy systemów w oparciu o AI
Obecny w rozwiązaniu potężny silnik analityczny, IBM SPSS Modeler, posiada ogromne możliwości i szerokie spektrum oferowanych algorytmów. Dzięki niemu użytkownik ma dostęp do narzędzi i technik wspomagających proces pozyskiwania danych z różnych źródeł, pozwalających na błyskawiczne zarządzanie ich jakością i przekształcenia. Dodatkowo PS CLEMENTINE Pack zawiera nowe procedury znacząco ułatwiające pracę z danymi oraz wbudowaną integrację silnika analitycznego z repozytorium.
Ułatwiona kontrola procesów i ich niezawodności
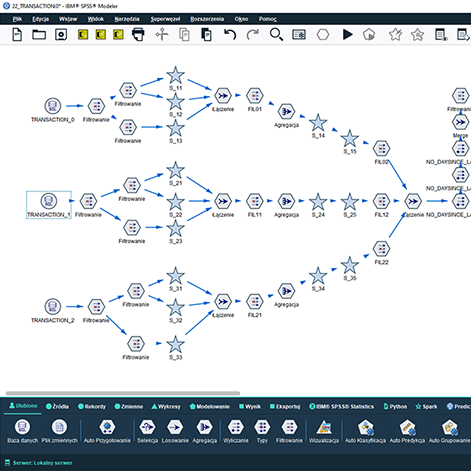
PS CLEMENTINE PRO to jedno z niewielu środowisk data science posługujących się koncepcją graficznego projektowania przepływu danych, przez co poszczególne operacje są widoczne, uporządkowane w logiczny ciąg, a całość przetwarzania poddaje się łatwej kontroli. Błędy w projektowaniu procedur widać jak na dłoni.
Integracja danych z wielu źródeł jednocześnie
Połączenie danych z bazy danych i pliku csv nigdy nie było prostsze. Operacje pobierania danych z tabel i widoków baz SQL-owych oraz innych środowisk analitycznych możliwe jest w ramach „tego samego obrazka”. Teraz również, dzięki PS CLEMENTINE PRO PACK, można pobrać dane z zewnętrznej bazy wysyłając do niej zapytanie SOAP.
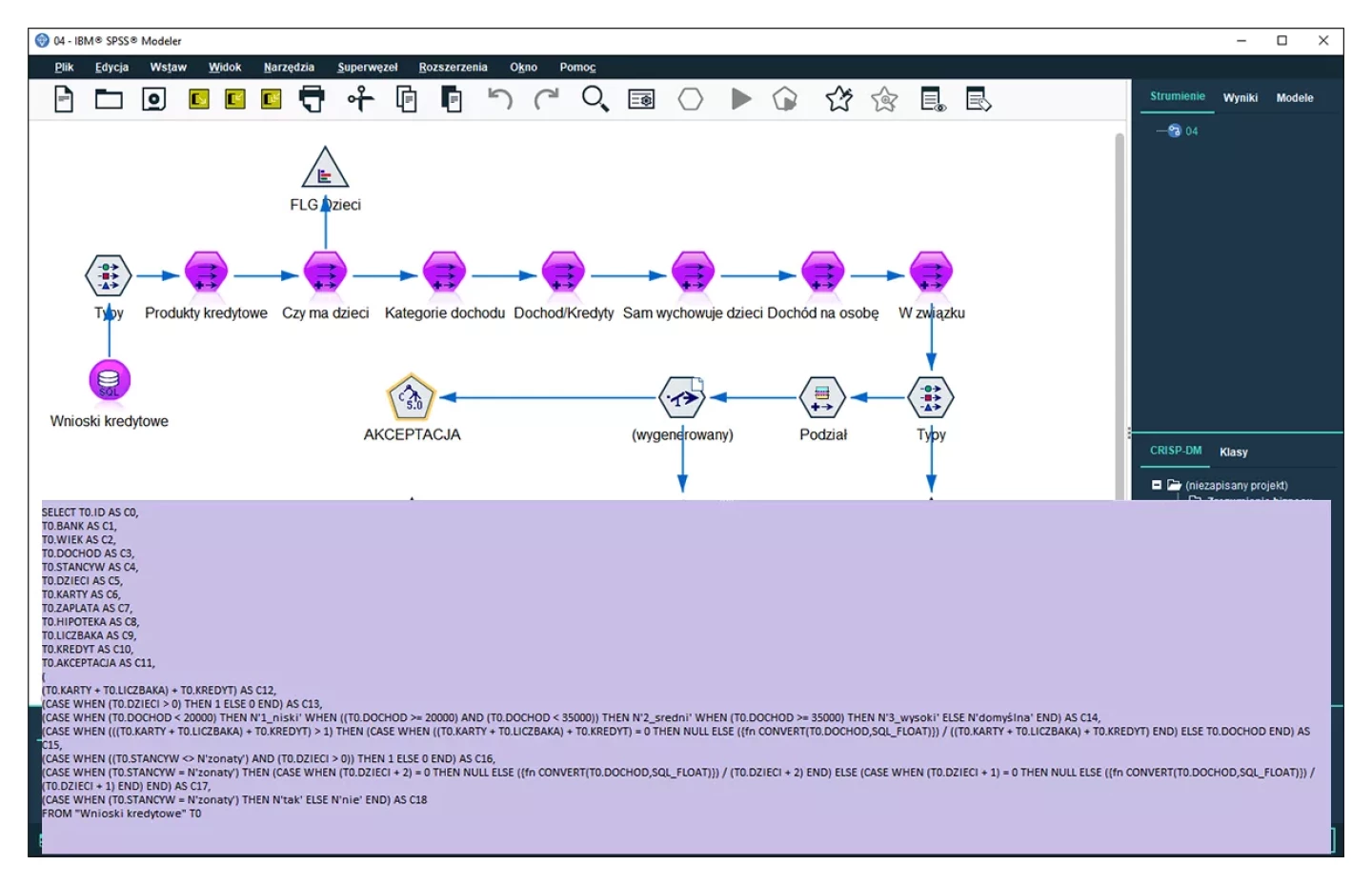
Rozszerzona współpraca z bazami danych – SQL Pushback
SQL Pushback to zaufana technologia współpracy z bazami danych, która oszczędza mnóstwo czasu wtedy gdy jest on analitykowi najbardziej potrzebny. PS CLEMENTINE PRO przepisze za nas złożone operacje transformacji danych na kod SQL, a baza danych te oparcie wykona. Użytkownik skupia się na eksploracji danych i nie musi jednocześnie sprawdzać składni zapytań.
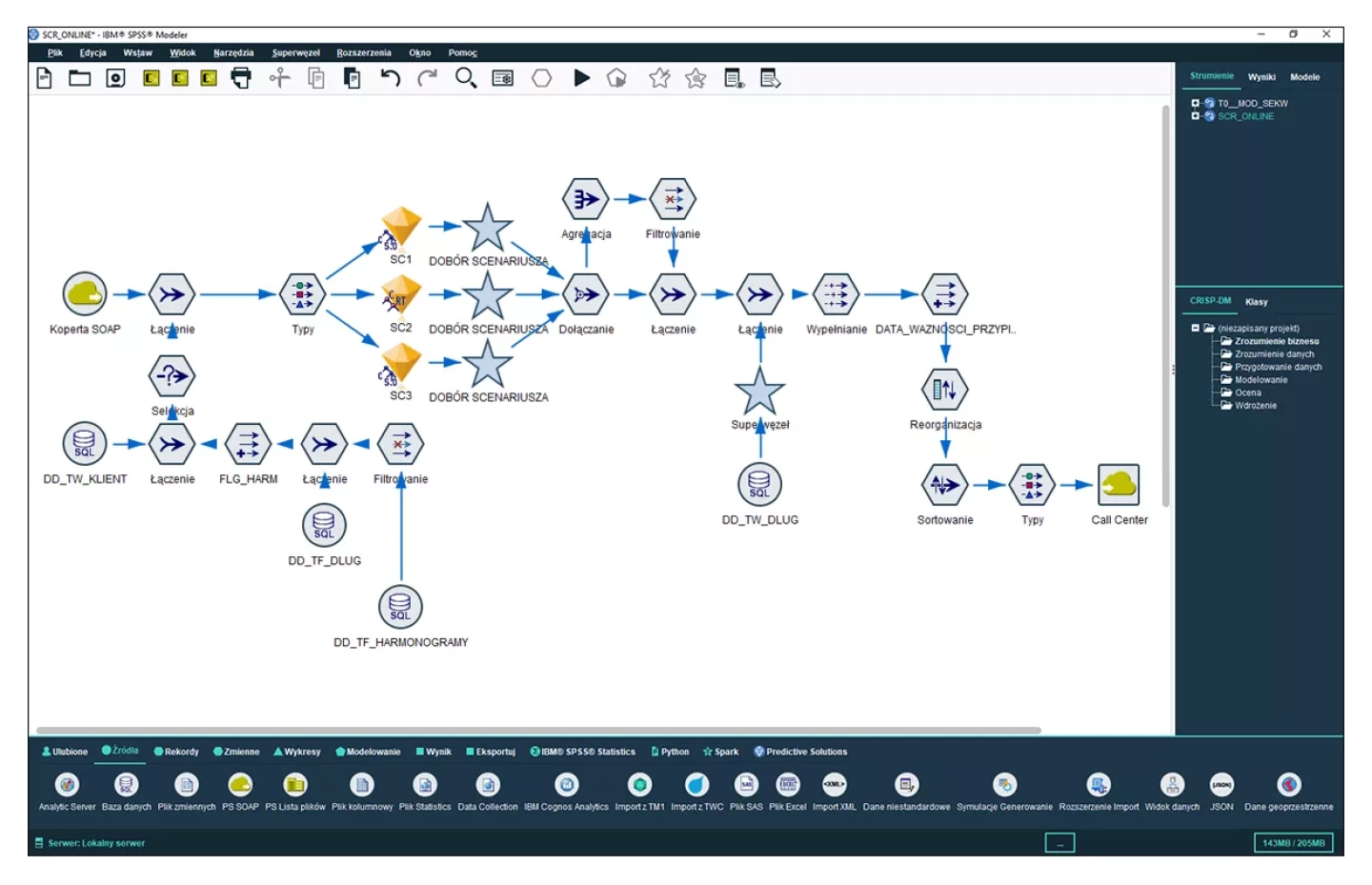
Real-time w praktyce
Płynny przepływ informacji we współczesnych systemach informacyjnych wymuszony jest koniecznością szybkiego reagowania na zdarzenia. Zbudowane systemy np. anty-fraud oparte o PS CLEMENTINE PRO i technologie real-time są dowodem, że można to robić skutecznie i na szeroką skalę. Z tego kierunku korzystają i duzi i mali użytkownicy PSCP.
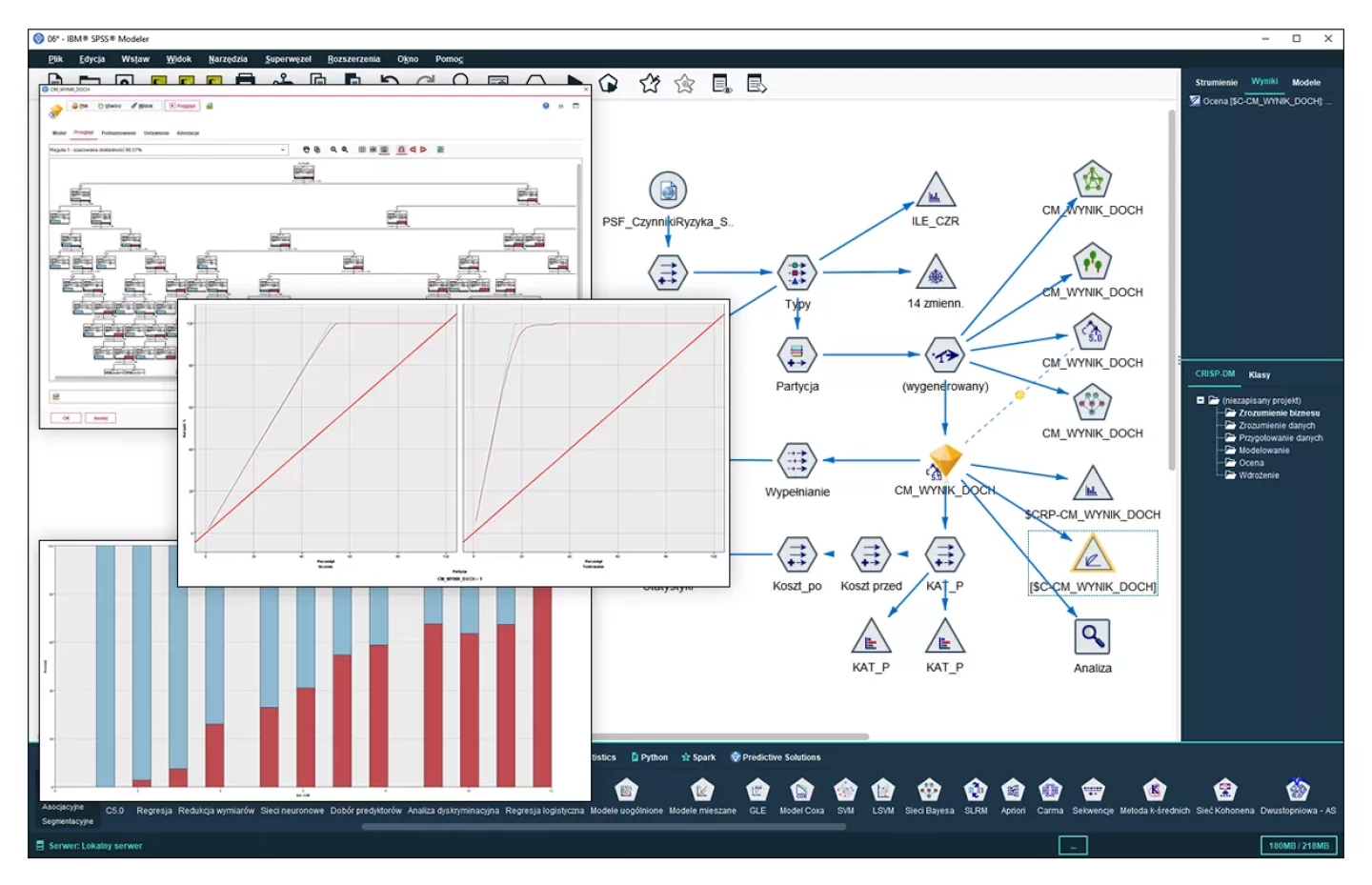
Zdobywanie wiedzy dzięki modelowaniu
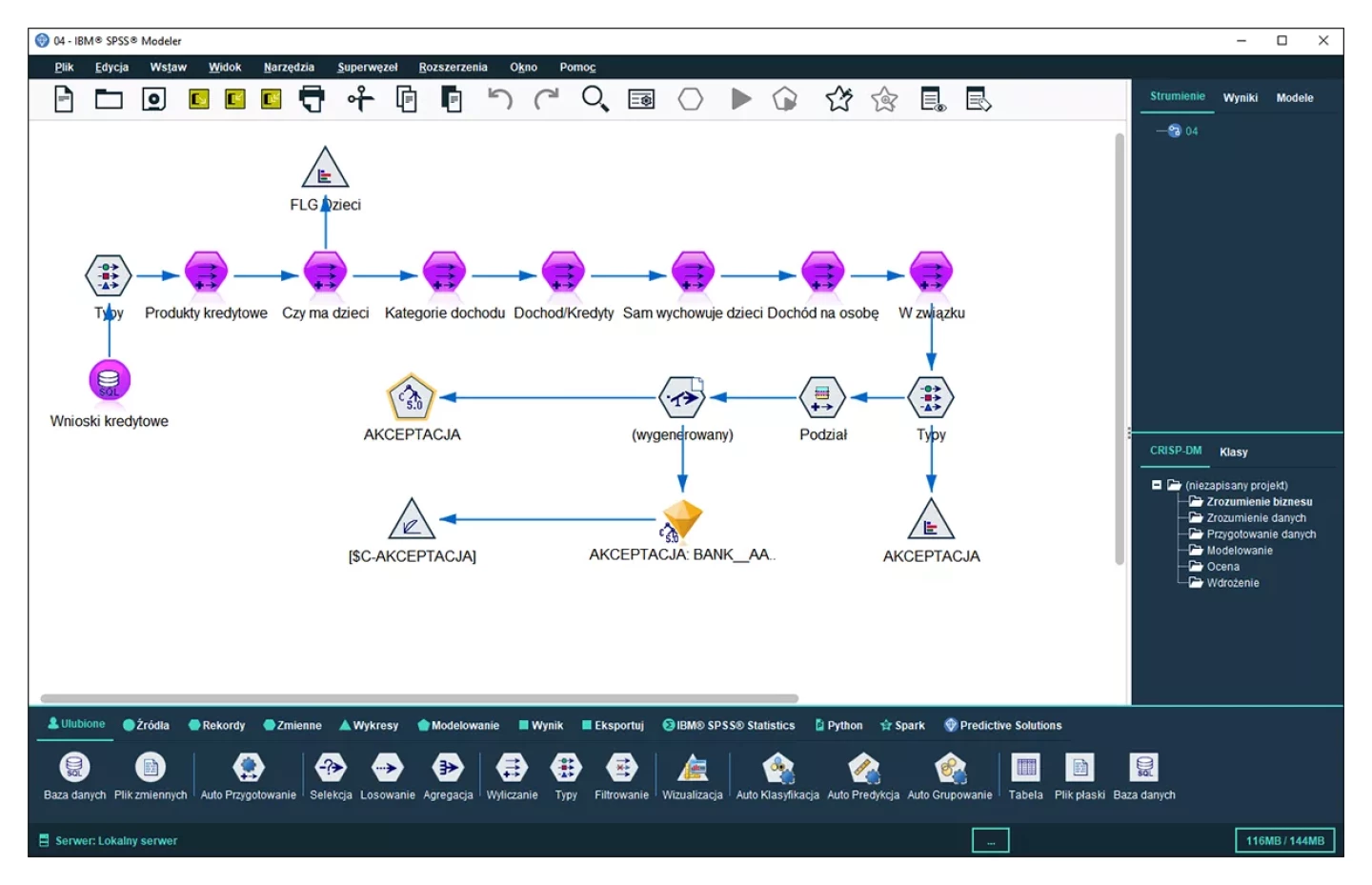
Szeroki zakres konfigurowalnych algorytmów, technik statystycznych i data mining pozwala na łączenie wiedzy z danych, wiedzy biznesowej i eksperckiej w ramach interaktywnego modelowania. PS CLEMENTINE PRO to system, który skupia w jednym środowisku zaawansowane techniki modelowania oparte o procedury statystyczne oraz sztuczną inteligencję. PS CLEMENTINE PRO oferuje kilkadziesiąt technik nadzorowanego uczenia wspierających tworzenie skoringów danych w pełnym spektrum zastosowań i branż, od kampanii marketingowych po fraud detection, w bankowości, FMCG, ubezpieczeniach, windykacji czy służbie zdrowia.
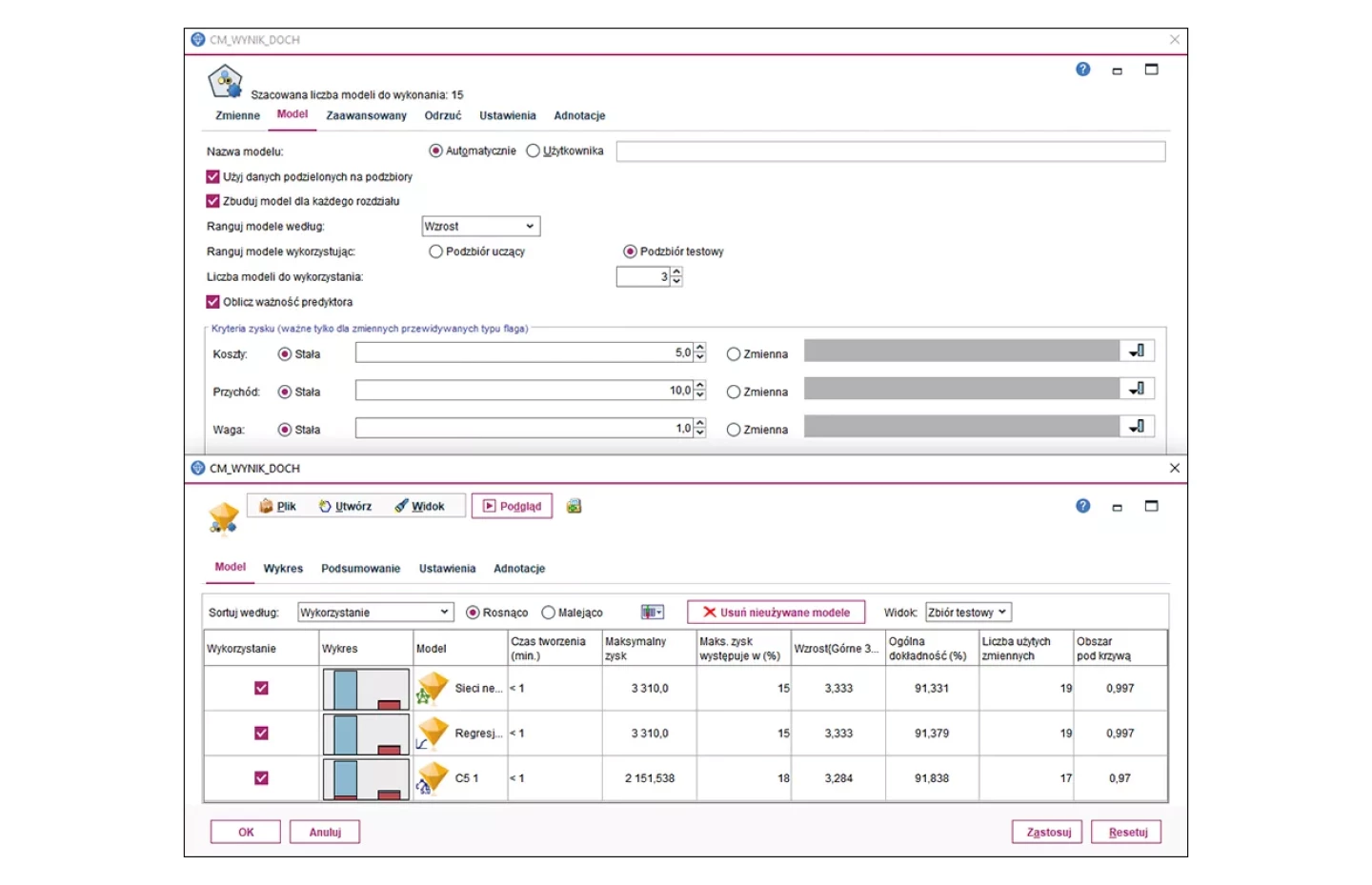
Automatyczne modele scoringowe
Wybór techniki modelowania nie zawsze jest prosty, nawet dla ekspertów w tej dziedzinie. PS CLEMENTINE PRO posiada specjalne narzędzia pozwalające na wczesnym etapie budowania modelu rozeznać się, które techniki poradzą sobie lepiej w określonych warunkach. Wykorzystanie węzłów automatycznego modelowania wydatnie skraca czas potrzebny na budowanie prototypowych modeli i współdziała z koncepcją MVP znaną ze zwinnych metodyk realizacji projektów.
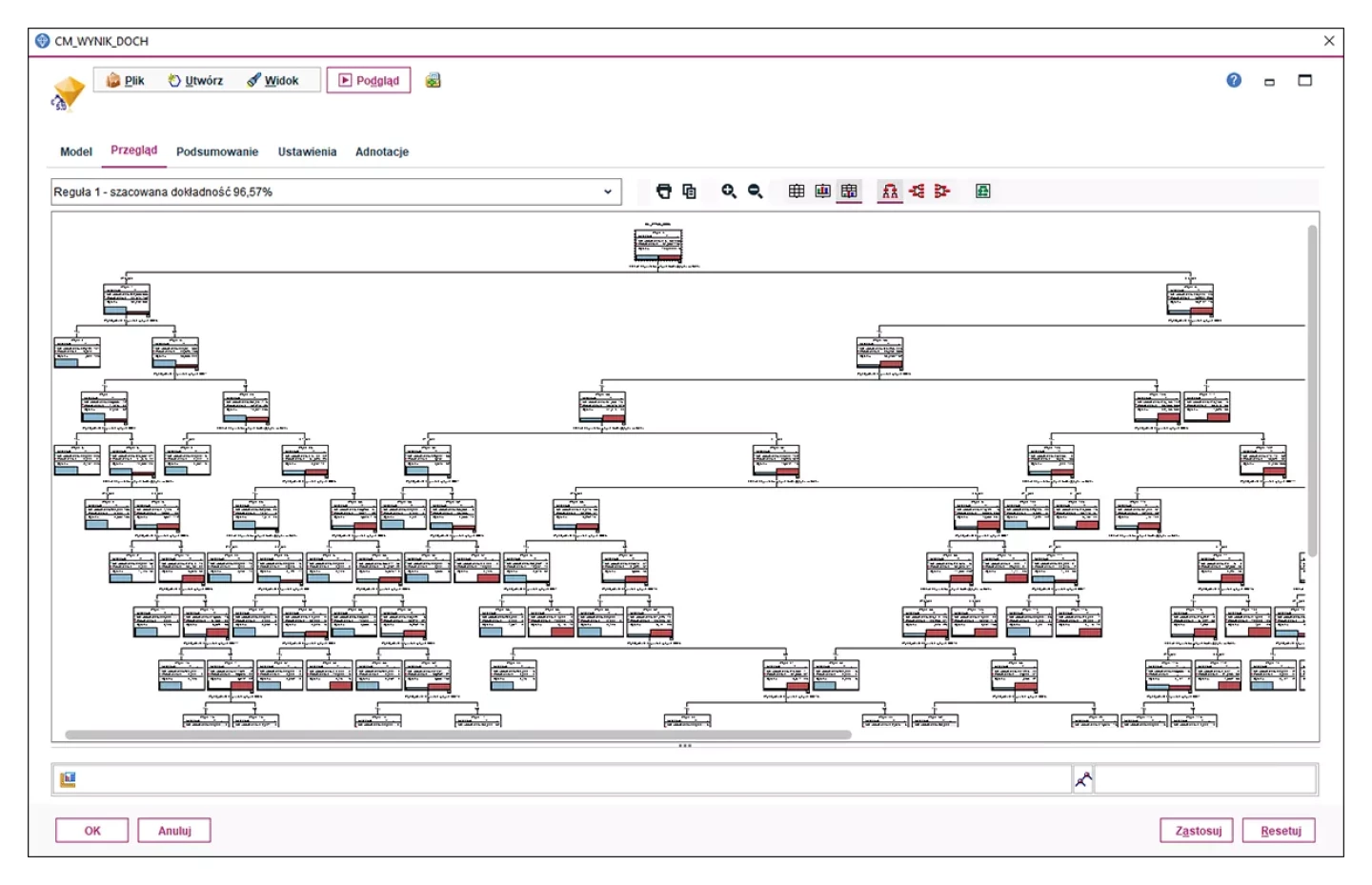
Dogłębne zrozumienie zależności
Cechą algorytmów analitycznych PS CLEMENTINE PRO są dobre ustawienia początkowe, choć nie w każdym przypadku zadziałają one tak samo dobrze. Dzięki rozbudowanym interfejsom wizualnym użytkownik może nadzorować model bazując na swojej wiedzy biznesowej.
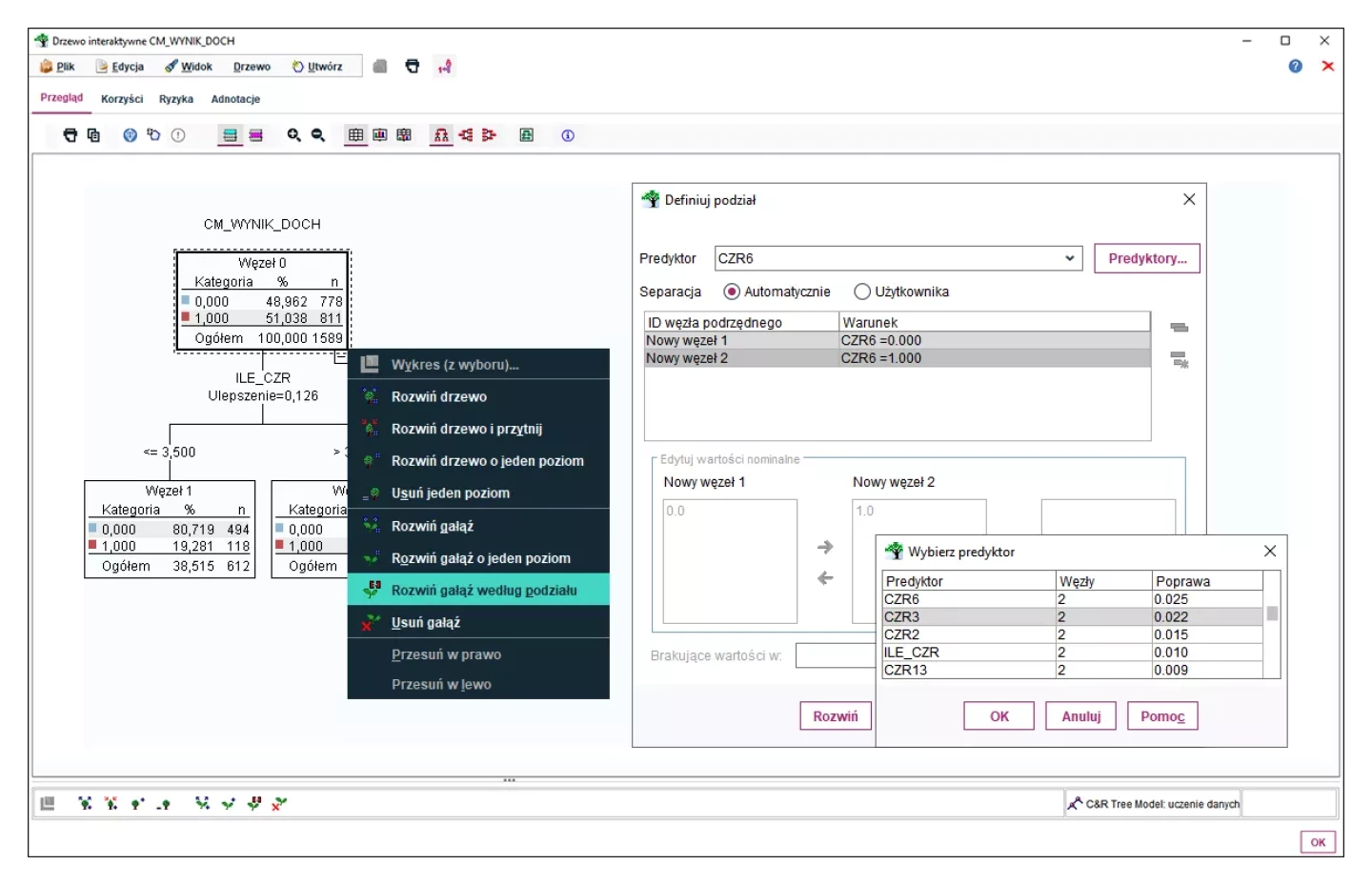
Interaktywna praca z algorytmami
Dostępna jest również opcja interaktywnego modelowania, dzięki której wiedza analityczna i biznesowa mogą się przenikać, w celu zbudowania rozwiązania dopasowanego do konktretnych, biznesowych warunków użycia. Jako użytkownik możesz sterować procesem wzrostu drzewa testując hipotezy o zależnościach – te które wydają ci się słuszne oraz te, z którymi trudno Ci się zgodzić, ale do tej pory nie mogłeś znaleźć na to argumentów, bo algorytmy, z których korzystałeś, były zamkniętymi czarnymi skrzynkami.
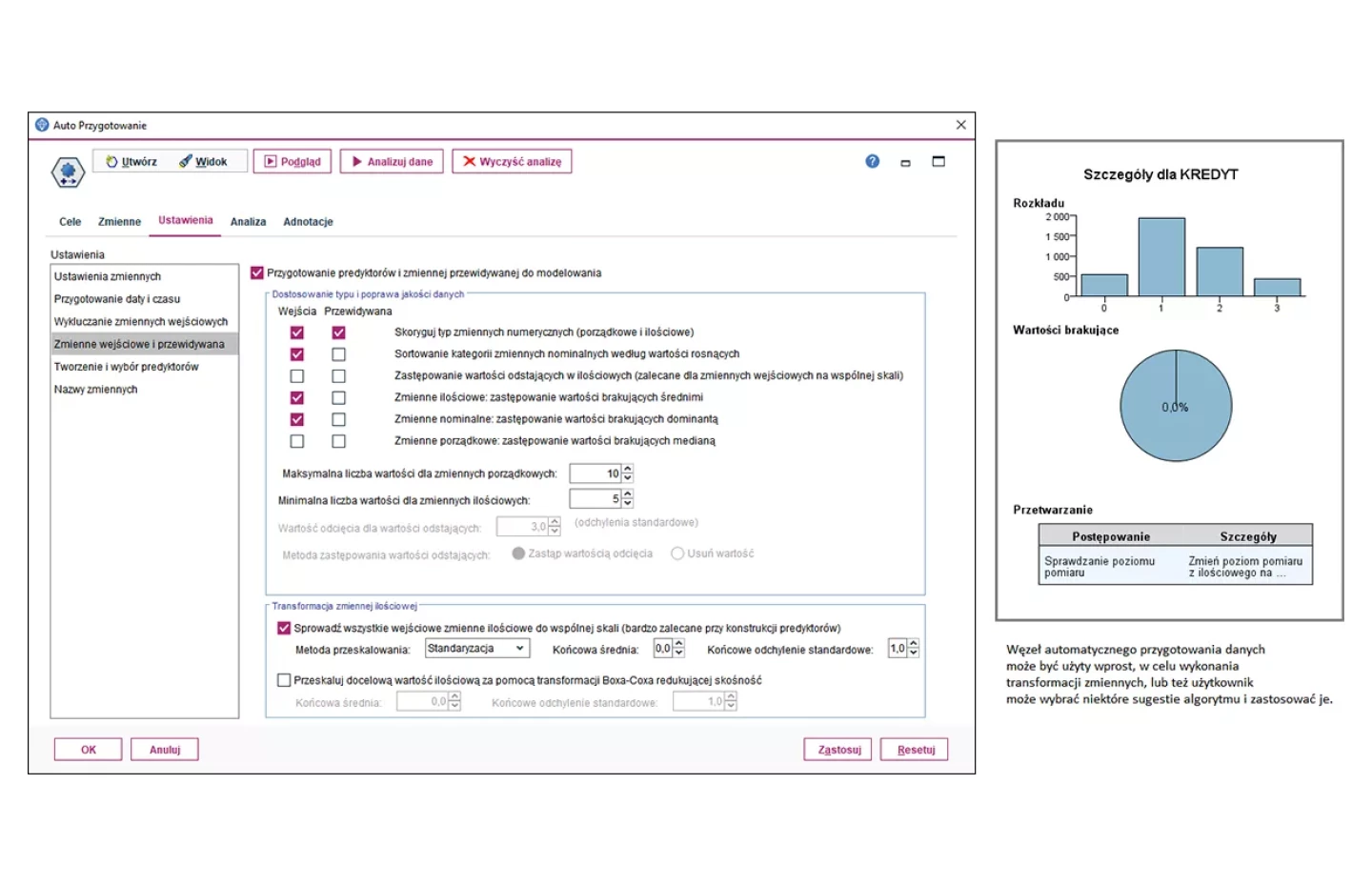
Automatyczne przygotowanie danych
PS CLEMENTINE PRO posiada algorytmy, które pomogą zrozumieć i skorygować dane, tak aby wykorzystać je optymalnie w modelowaniu. Zamiast zastanawiać się jakiej transformacji użyć, możesz od razu zobaczyć jej efekt i ocenić wpływ na Twój docelowy model. Wystarczy Twoja zgoda aby system wykorzystał przekształcone dane do budowania ostatecznego modelu.
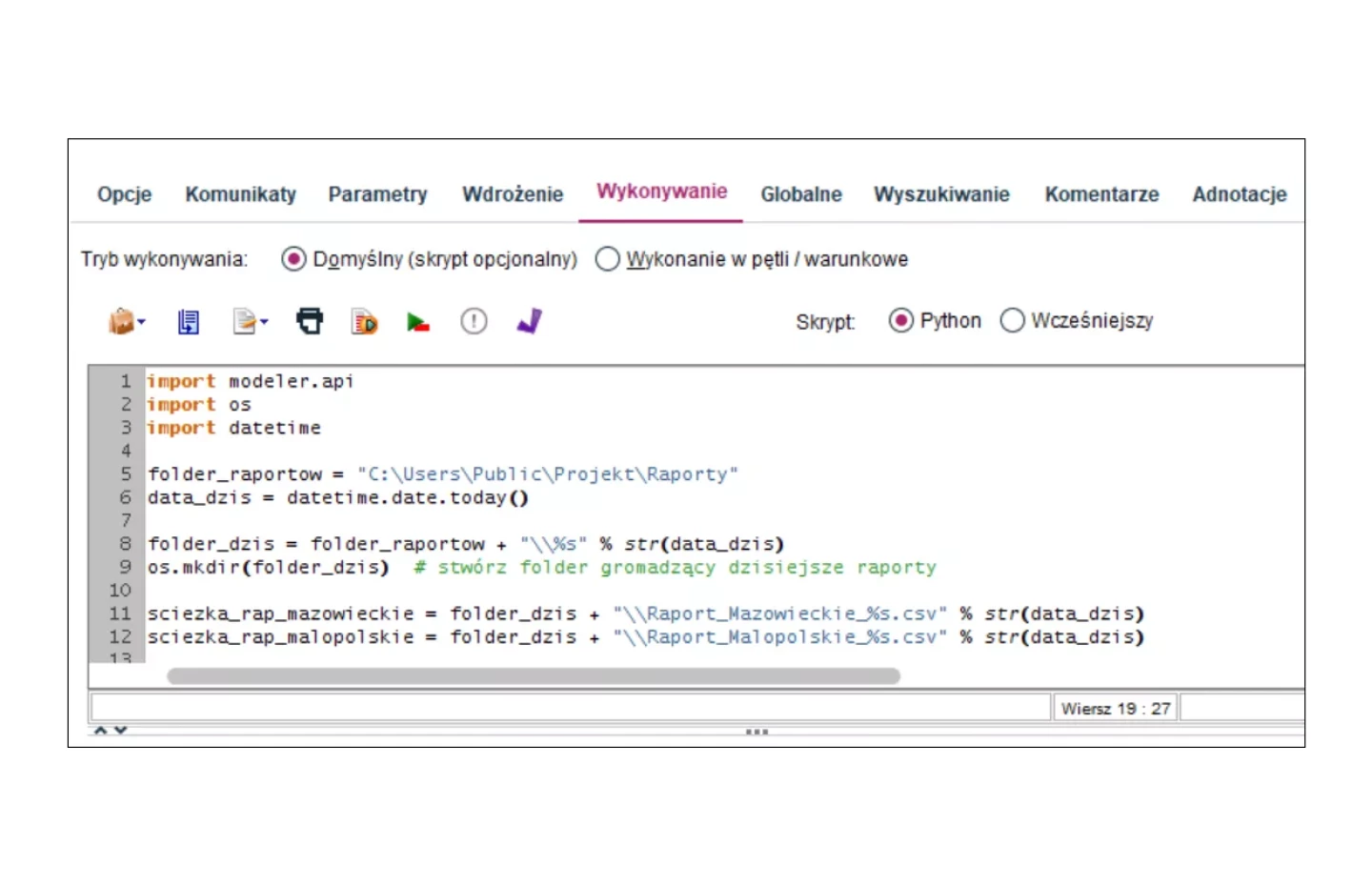
Współpraca z R i Python
PS CLEMENTINE PRO jest liderem we współpracy z zewnętrznymi środowiskami analitycznymi. Węzły rozszerzeń pozwalają korzystać z bibliotek i tworzyć własne procedury w oparciu o język R i Python (Spark). Implementacja skryptów może polegać na łatwym (drag and drop) stworzeniu własnego interfejsu węzła dostosowanego do wymagań skryptu, po to aby każdy mógł z niego skorzystać. Przykłady takich narzędzi znajdują się w „Centrum rozszerzeń” i można je pobrać wprost do PS CLEMENTINE PRO.
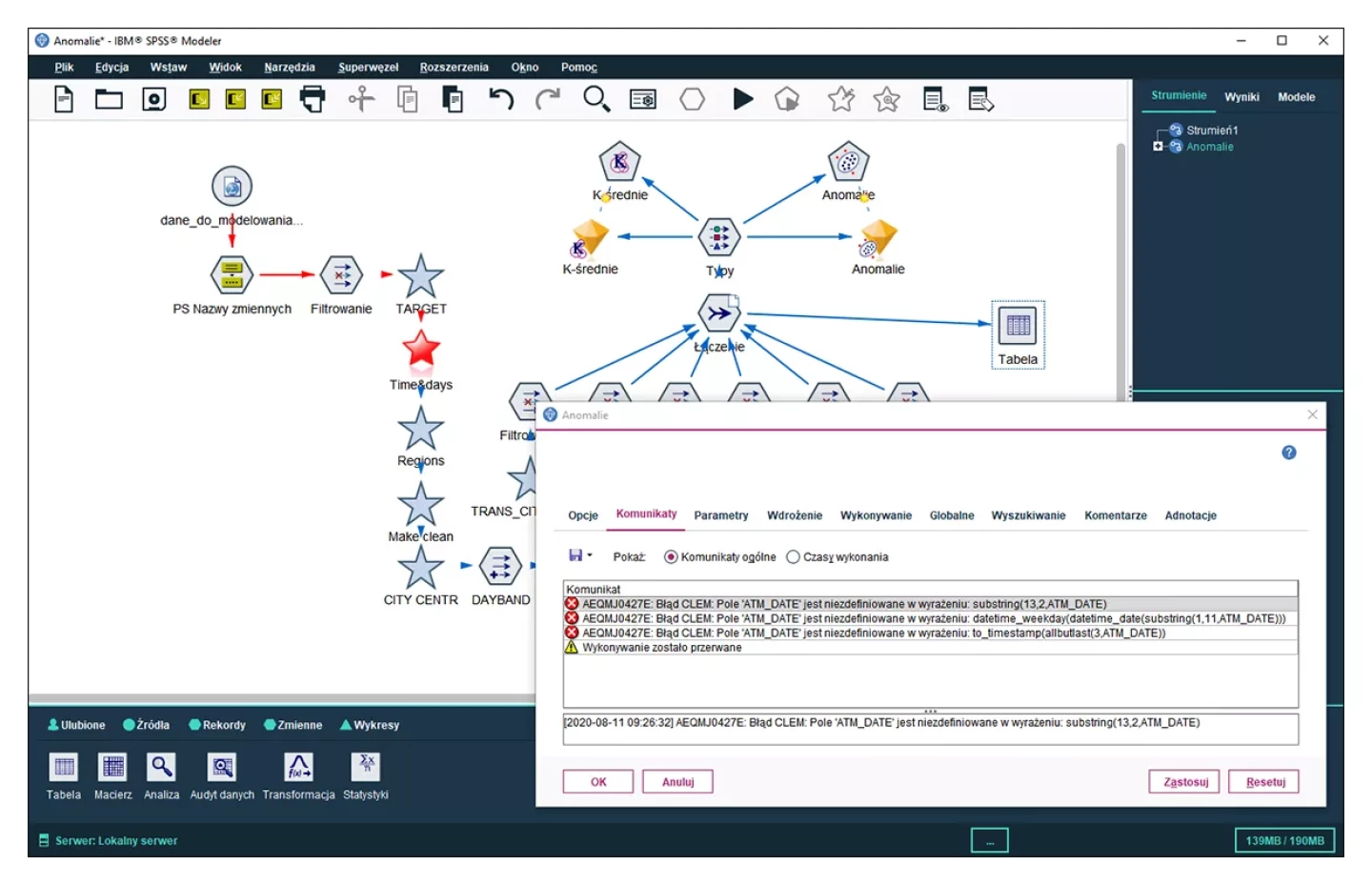
Zarządzanie procesem analitycznym
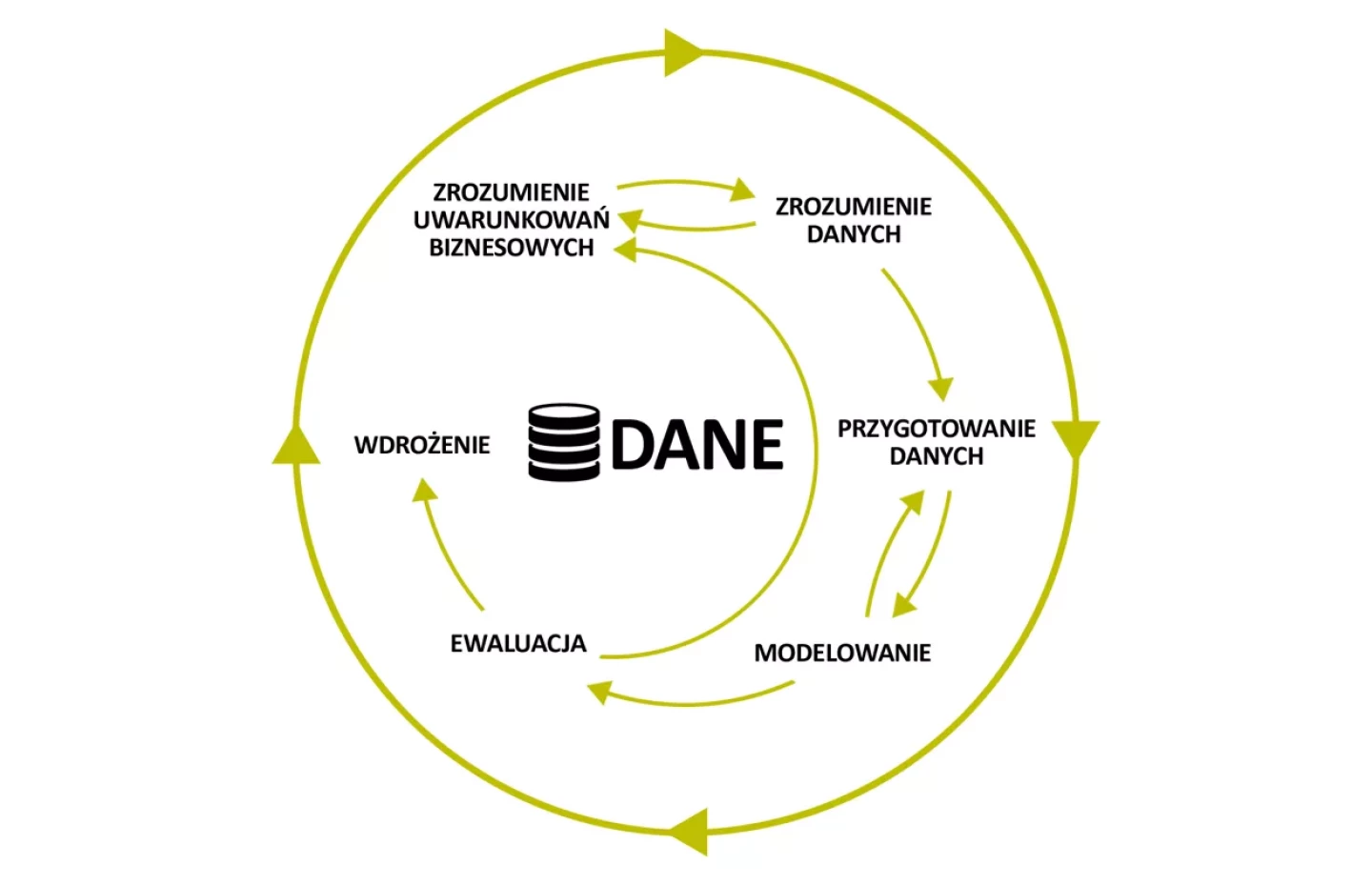
PS CLEMENTINE PRO jest narzędziem dostosowanym do wymogów sprawdzonej metodologii prowadzenia projektów data mining (CRISP-DM). Pozwala na jasne i przejrzyste prezentowanie procesu analizy oraz jego dokumentację.
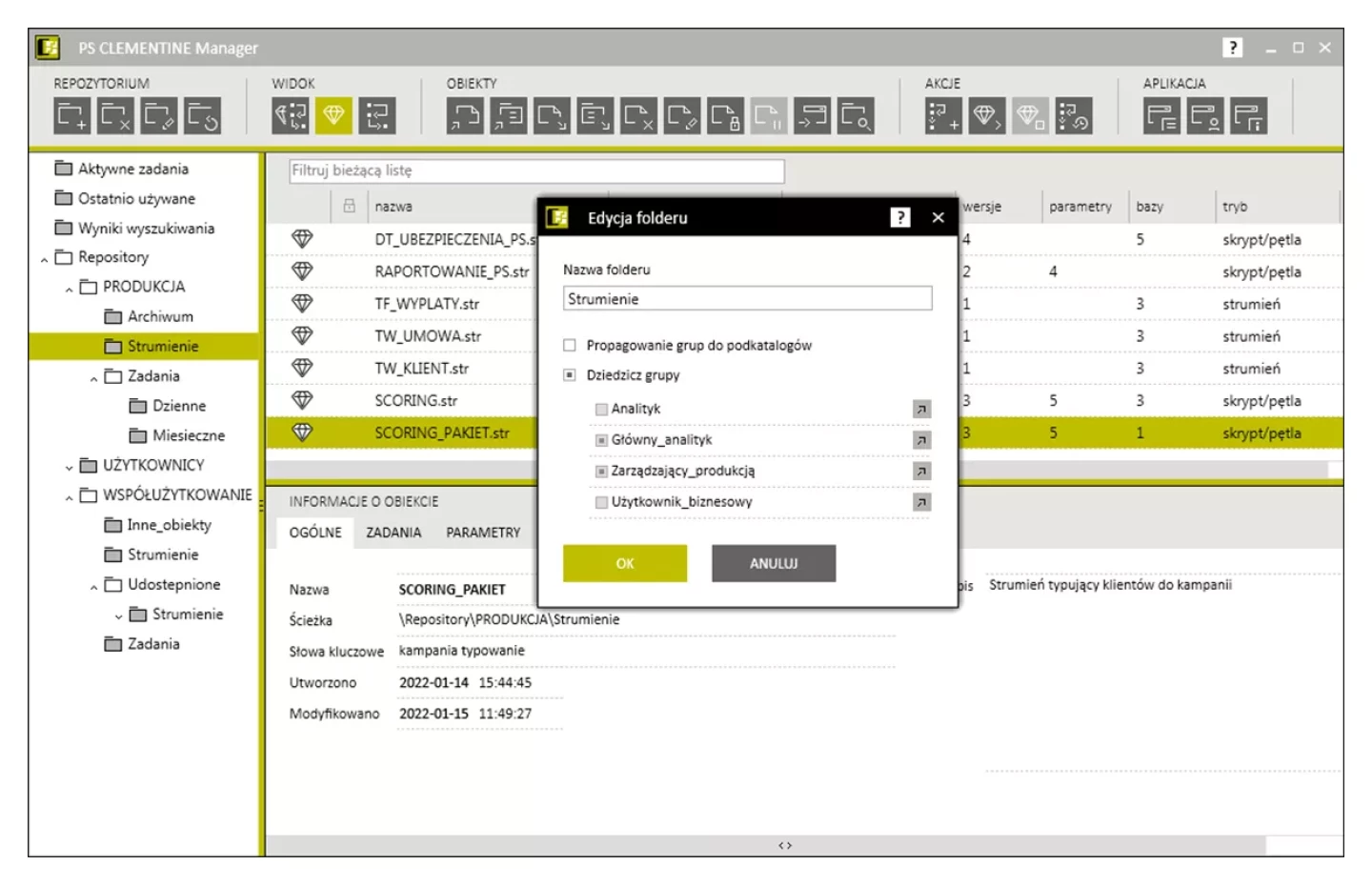
Praca grupowa oraz zarządzanie pracą zespołu
PS CLEMENTINE PRO dzięki wbudowanemu repozytorium analitycznemu pozwala na scentralizowane zarządzanie procesem analitycznym. Posiada funkcjonalności, dzięki którym możliwe jest zróżnicowanie użytkownikom dostępu do zasobów w zależności od pełnionej roli i posiadanych kompetencji. To stwarza pole do ustrukturyzowanej pracy grupowej. Rozwiązanie to w znakomity sposób usprawnia pracę w zakresie organizacji, przechowywania i udostępniania treści analitycznych.
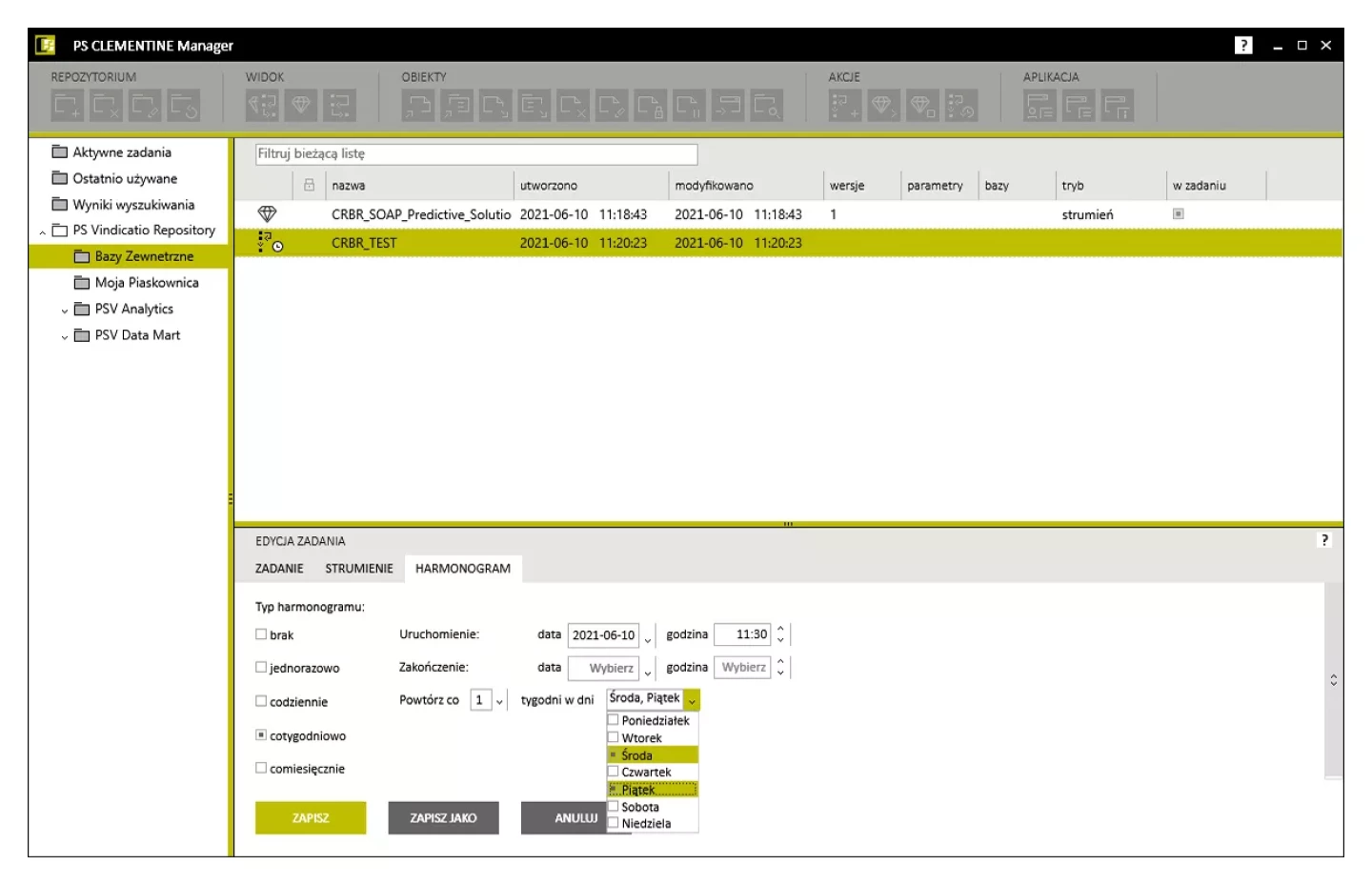
Automatyzacja procesów - elastyczne harmonogramowanie zadań
PS CLEMENTINE PRO umożliwia automatyczne wykonywanie procesów zgodnie ze zdefiniowanym harmonogramem. Ponadstandardowe możliwości ustawiania harmonogramu obejmują uruchomienie procesu np. w ostatnią środę miesiąca, we wskazane dni w tygodniu, np. poniedziałek i piątek lub co trzeci dzień
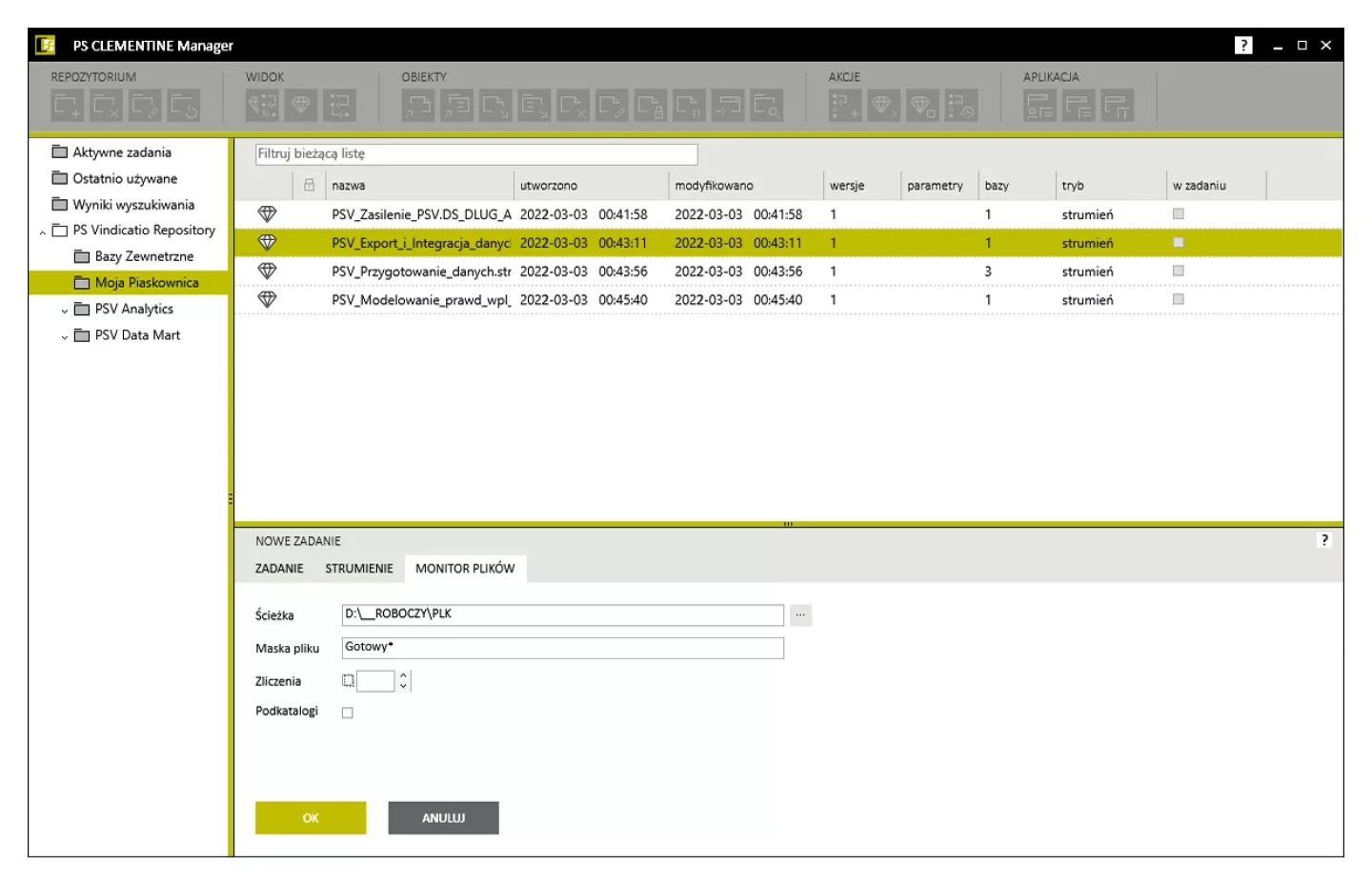
Automatyzacja procesów – wyzwalanie inicjowane plikiem
PS CLEMENTINE PRO pozwala uruchamiać procesy przetwarzania danych również na żądanie, np. wtedy gdy w określonej lokalizacji pojawi się plik o zdefiniowanych parametrach. Usprawnia to wypełnianie danymi repozytoriów analitycznych, które zazwyczaj muszą czekać ze startem swoich procesów zasilania aż zakończą się procesy zasilania hurtowni centralnej. Z PS CLEMENTINE PRO łatwo stworzysz asynchroniczne procesy zasilające.
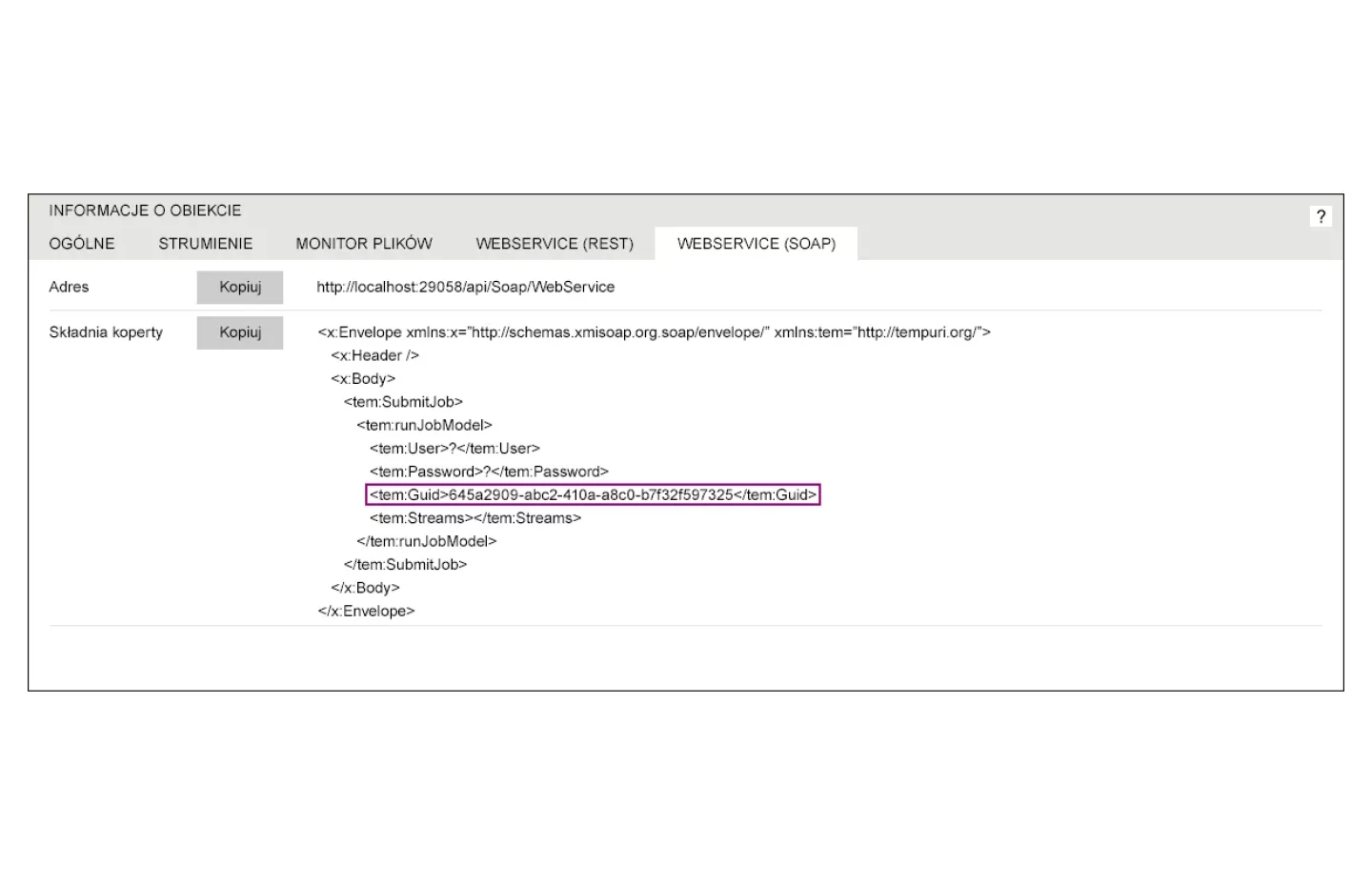
Automatyzacja procesów – wyzwalanie inicjowane nadejściem zapytania
PS CLEMENTINE PRO oferuje również możliwość uruchamiania zadań przetwarzania i skoringu danych w odpowiedzi na komunikat Web Service, np. gdy, dane Klienta muszą zostać zaktualizowane w momencie pojawienia się Klienta w nowym kanale. W takim przypadku kanał wysyła zapytanie o dane klienta, a nasłuchujące środowisko analityczne uruchamia proces zbierania aktualnych danych lub scoring w celu dopasowania najlepszej oferty.
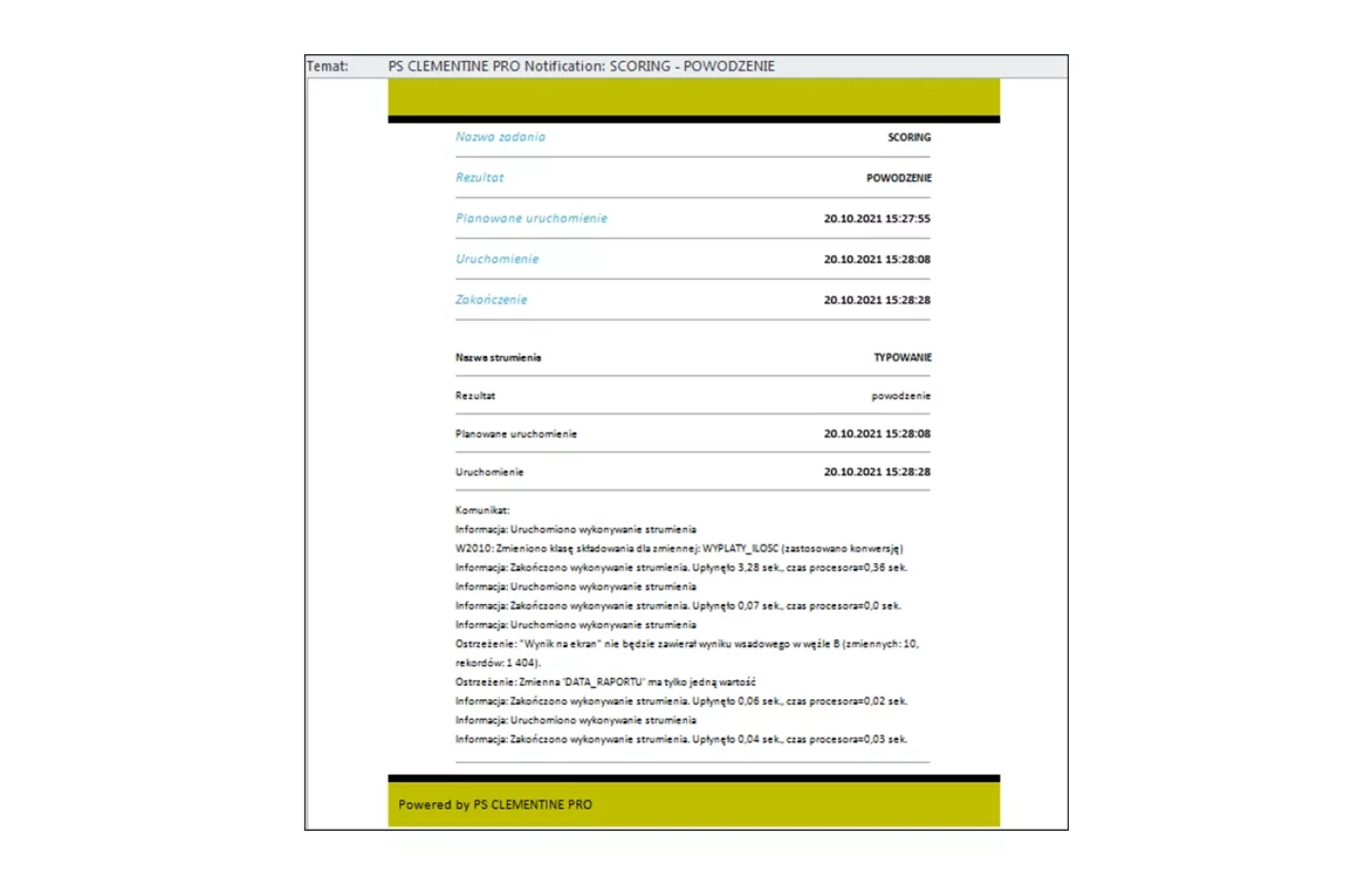
Automatyzacja procesów – kontrola dzięki notyfikacjom e-mail
Status zakończenia realizacji zadania komunikowany jest wskazanym odbiorcom poprzez bezpieczną wiadomość e-mail rozsyłaną z wewnętrznego serwera pocztowego SMTP.
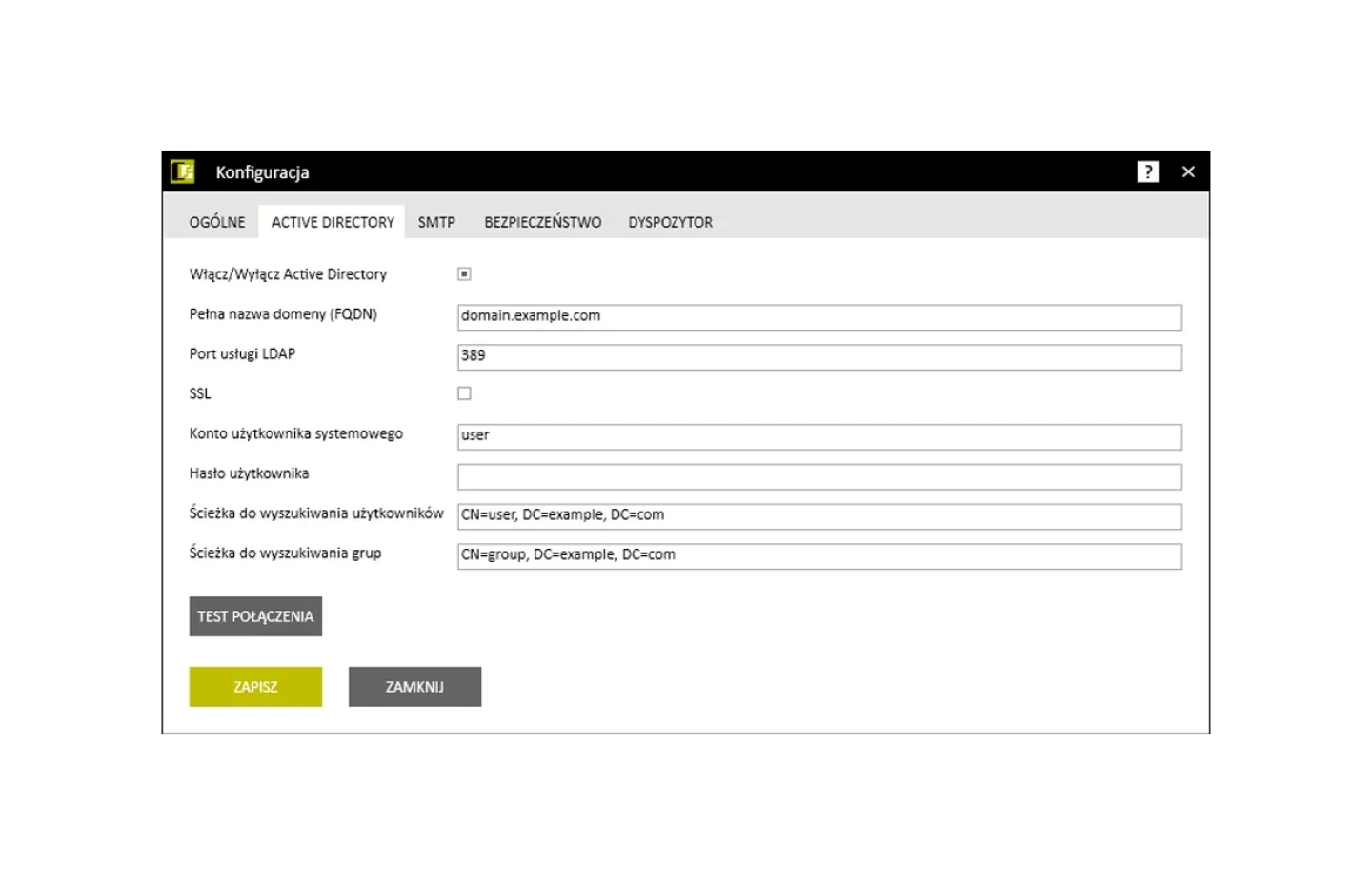
Szybka integracja z systemami zarządzania uprawnieniami użytkowników
PS CLEMENTINE PRO może korzystać z informacji usługi katalogowej Active Directory i przejąć ustawienia hierarchii i uprawnień użytkowników. Opcja ta jest wbudowana w PS CLEMENTINE PRO i nie wymaga developementu.
Nowości w wersji 5.0
Stale rozwijamy nasze produkty,
by Twoje dane jeszcze lepiej pracowały dla Ciebie.
- NOWY INTERFEJS APLIKACJI
- MOŻLIWOŚĆ GRAFICZNEGO TWORZENIA DIAGRAMÓW PRZEPŁYWU REALIZACJI ZADANIA
- PRACA Z NOWYMI FORMATAMI PLIKÓW
- NOWY SILNIK ANALITYCZNY – IBM SPSS MODELER 18.5.0.
- WSPARCIE DLA KOLEJNYCH SYSTEMÓW I TECHNOLOGII
Szkolenia
Linia kursów data mining pokazuje, jak wiele informacji można uzyskać z istniejących danych i jak za ich pomocą budować modele predykcyjne. Uczymy jak w praktyce realizować projekty data mining, by zbudowane w ich trakcie modele pracowały na rzecz instytucji. Na przykład typując klientów do kampanii i rekomendując dla nich określone działania.
Kursy tej serii podchodzą do zagadnień data mining kompleksowo, omawiając każdy z etapów. Począwszy od audytu i przygotowania danych, poprzez budowę i ewaluację modelu, a na integracji modeli z systemami informatycznymi kończąc.
DM 2. Data mining, zrozumienie, ocena jakości i przygotowanie danych do modelowania
Zawartość kursów niestandardowych może obejmować połączone plany kilku szkoleń lub wybrane zagadnienia. Pozwala to naszym klientom w sposób niemal idealny dopasować szkolenie do własnych potrzeb.
Opinie
Trudno przecenić korzyści płynące z możliwości wykonywania skomplikowanych operacji na ogromnych wolumenach danych samodzielnie przez osobę, która bezpośrednio korzysta z wyników w sposób łatwy i szybki z użyciem informacji zwrotnych.

W projekcie wykorzystaliśmy system PS CLEMENTINE PRO do pobierania i łączenia danych, a także ich przekształcania i analizy. Prace analityczne były skupione na wyszukiwaniu podejrzanych wzorców (sekwencji zdarzeń), czynników ryzyka oraz anomalii (nietypowych zachowań).
