Wypływ braków danych na wyniki prowadzonych analiz
Braki danych mogą mieć duży wpływ na wyniki analizy danych. Mogą prowadzić do zniekształcenia wyników, gdyż pomijają istotne informacje. Jeśli braki danych nie są odpowiednio uwzględnione, analiza może być niepełna lub nawet błędna. Z drugiej strony, wyłączenie braków danych może prowadzić do utraty cennych informacji, co może ograniczyć wiarygodność wyników. Warto również pamiętać, że imputowanie niekompletnych informacji nie zawsze jest bezbłędne i może wprowadzać pewne ryzyko zniekształceń.
Do głównych problemów, które wynikają z braków danych, należy zaliczyć:
- Zmniejszenie dokładności analiz i mocy statystycznej: brak danych często prowadzi do zmniejszenia próby użytej w analizie, co może zmniejszyć moc statystyczną testów. Mniejsza moc statystyczna oznacza większe ryzyko popełnienia błędu II rodzaju i nieodkrycie istotnych efektów lub różnic, które w rzeczywistości występują[1]. W przypadku występowania dużych ilości braków danych dokładność analizy może być znacząco zmniejszona, co ogranicza wiarygodność wyników.
- Zniekształcenie wyników: niekompletne informacje mogą skutkować niedokładnymi lub zniekształconymi wynikami analizy, ponieważ pomijają istotne dane, co może prowadzić do błędnych wniosków. Braki danych powodują utratę cennych informacji, które mogłyby być istotne dla analizy i zrozumienia badanych zjawisk.
- Wpływ na modele predykcyjne: w przypadku analizy danych za pomocą modeli predykcyjnych, braki mogą prowadzić do pogorszenia jakości predykcji, gdyż modele mogą być uczone na niepełnych danych.
Aby wybrać odpowiednią metodę obsługi braków danych, należy dokładnie zrozumieć ich naturę oraz przyczynę.
Podstawowe typy braków danych
Najbardziej popularny podział braków danych, jaki można spotkać w literaturze, odnosi się do tego, czy są one wynikiem przypadku – czy są losowe, czy nie, a także czy na ich powystawianie mają wpływ inne czynniki. Określenie mechanizmów ich powstania i wskazanie, z jakim typem braków ma styczność analityk, jest ważne, aby wybrać odpowiednie metody radzenia sobie z nimi.
Braki danych dzielimy na[2]:
- MCAR (Missing Completely At Random): braki danych są całkowicie losowe i nie zależą od żadnych innych wartości w zbiorze danych. Oznacza to, że prawdopodobieństwo braku danych jest takie samo dla wszystkich obserwacji, niezależnie od wartości zarówno obserwowanych, jak i nieobserwowanych danych.
Przyjrzyjmy się tabeli 1, w której mamy kilka zmiennych: wiek, wykształcenie oraz dochód. Braki danych w kolumnie „Wiek” mogą być przykładem MCAR, zakładając, że brak tej wartości jest całkowicie losowy i nie zależy od innych zmiennych w zbiorze danych. Przykładem może być sytuacja, gdy respondent przypadkowo pomija odpowiedź na pytanie o wiek w ankiecie.
- MAR (Missing At Random): braki są losowe, ale ich występowanie może zależeć od innych obserwowanych danych w zbiorze, ale nie od wartości brakujących danych.
Niekompletne informacje w kolumnie „Dochód” mogą być przykładem braków typu MAR, jeżeli założymy, że prawdopodobieństwo braku odpowiedzi na pytanie o dochód zwiększa się z wiekiem respondentów. Jednak samo prawdopodobieństwo braku danych nie zależy bezpośrednio od nieznanych wartości dochodu.
- MNAR (Missing Not At Random): Braki danych nie są losowe i prawdopodobieństwo ich wystąpienia zależy od wartości brakujących danych w samych sobie.
Niekompletne informacje w kolumnie „Wykształcenie” mogą być przykładem MNAR, jeśli założymy, że im niższe wykształcenie, tym bardziej prawdopodobne jest, że dane dotyczące wykształcenia nie zostaną podane. W tym przypadku brak jest bezpośrednio związany z wartością, która powinna być podana, co wprowadza systematyczny błąd w brakujących danych.
|
LP |
Wiek |
Wykształcenie |
Dochód |
|
1 |
25 |
NA |
4000 |
|
2 |
NA |
NA |
4500 |
|
3 |
35 |
Średnie |
NA |
|
4 |
45 |
Wyższe |
5500 |
|
5 |
55 |
Wyższe |
NA |
* NA (Not Available) – oznaczenie braków danych
Rozpoznanie typu braków danych w analizowanym zbiorze jest kluczowe dla wyboru odpowiedniej metody ich obsługi. Każdy z nich wymaga innej strategii, aby analiza była wiarygodna, a wnioski z niej płynące – poprawne i jakościowe.
Metody radzenia sobie z brakami danych
Sposoby radzenia sobie z brakami danych obejmują różnorodne podejścia, od bardzo prostych po złożone metody imputacji. Każdy z wymienionych rodzajów ma swoje zalety i ograniczenia. Jednym z podstawowych podejść jest usuwanie lub pomijanie danych, w których występują braki. Z kolei do bardziej złożonych metod możemy zaliczyć imputację danych, która jest często stosowana. Zarówno modele statystyczne, jak i algorytmy uczenia maszynowego, wymagają starannego doboru i walidacji. Jest to potrzebne, aby upewnić się, że proces imputacji nie wprowadza dodatkowych błędów czy stronniczości. Kluczowe jest również zrozumienie mechanizmu, który doprowadził do braku danych, ponieważ różne mechanizmy mogą wymagać zastosowania różnych strategii radzenia sobie z nimi.
Popularne metody postępowania z brakami danych:
- Usuwanie i pomijanie danych: w przypadku usuwania obserwacji z brakami danych, są one usuwane z analizowanego zbioru danych. Z kolei przy pomijaniu danych, obserwacje z brakami pozostają w zbiorze, ale nie są brane pod uwagę w analizie, pozwalając analitykowi zachować opcję ich wykorzystania w dalszych badaniach. Metoda ta może prowadzić do utraty informacji, a model statystyczny utworzony na takich danych może być niedokładny. Podejście jest zasadne, tylko jeżeli braki są typu MCAR. Jeśli braki danych nie są całkowicie losowe, nie można bezpiecznie usuwać obserwacji z brakami wartości lub podstawiać braków danych pojedynczo. W takich sytuacjach należy wykorzystać wielokrotną imputację. W sytuacji MCAR przy małej liczbie braków danych wykluczanie jednostek obserwacji z analizy nie doprowadzi do znacznych obciążeń estymacji parametrów i może być stosowane.
- Imputacja pojedyncza: brakujące dane mogą być zastępowane wartościami wyliczonymi z istniejących. Brakujące wartości są zastępowane stałą wartością, np. średnią, medianą lub dominantą dla danej zmiennej. Mogą być także przewidywane za pomocą regresji liniowej lub innych technik regresji na podstawie dostępnych danych. Warto jednak pamiętać, że podstawianie danych ze średniej lub mediany może powodować, że rozkład będzie zniekształcony i dane będą niereprezentatywne, szczególnie jeśli dane nie są brakami losowymi.
- Imputacja wielokrotna: dla każdej brakującej wartości generuje się kilka możliwych zastępczych wartości, tworząc w ten sposób wiele kompletnych zestawów danych. Każdy z nich jest następnie analizowany oddzielnie, a wyniki tych analiz są łączone, aby uzyskać ostateczne estymacje i wnioski, które uwzględniają niepewność związaną z brakującymi danymi. Zaletą imputacji wielokrotnej jest to, że pozwala ona na oszacowanie nie tylko wartości brakujących danych, ale także niepewności związanej z tymi estymacjami. Dzięki temu podejściu wyniki analiz są wiarygodne i mniej podatne na potencjalne błędy wynikające z arbitralnego wyboru pojedynczej wartości dla brakujących danych. Imputacja wielokrotna jest szczególnie przydatna w badaniach, gdzie braki danych są nieuniknione, a ich pominięcie lub niewłaściwe obsłużenie mogłoby prowadzić do błędnych wniosków. Metoda ta uwzględnia wzajemne zależności między zmiennymi w zbiorze danych, co pozwala na dokładne estymowanie brakujących wartości.
Imputacja braków danych w PS IMAGO PRO
PS IMAGO PRO pozwala na zastosowanie wielu metod radzenia sobie z brakami danych, w tym również tych wspomnianych powyżej. Analityk może pomijać obserwacje z brakami danych bezpośrednio w oknie procedur analitycznych. Wybrane obserwacje, które mają zbyt dużą liczbę braków danych, można szybko odnaleźć i je usunąć, jeśli taki scenariusz pracy zostanie wybrany. W przypadku imputacji pojedynczej, korzystając z procedury Analiza braków danych, możemy zadbać o jakość danych i rzetelnie weryfikować oraz zastępować braki. Ta funkcjonalność pozwoli:
- otrzymać dokładne statystyki dotyczące wzorców występowania braków danych,
- otrzymać oszacowania statystyk dla różnych metod określania braków,
- sprawdzić, czy braki danych są losowe,
- dokonać pojedynczych podstawień braków (przy użyciu metody regresji lub EM).
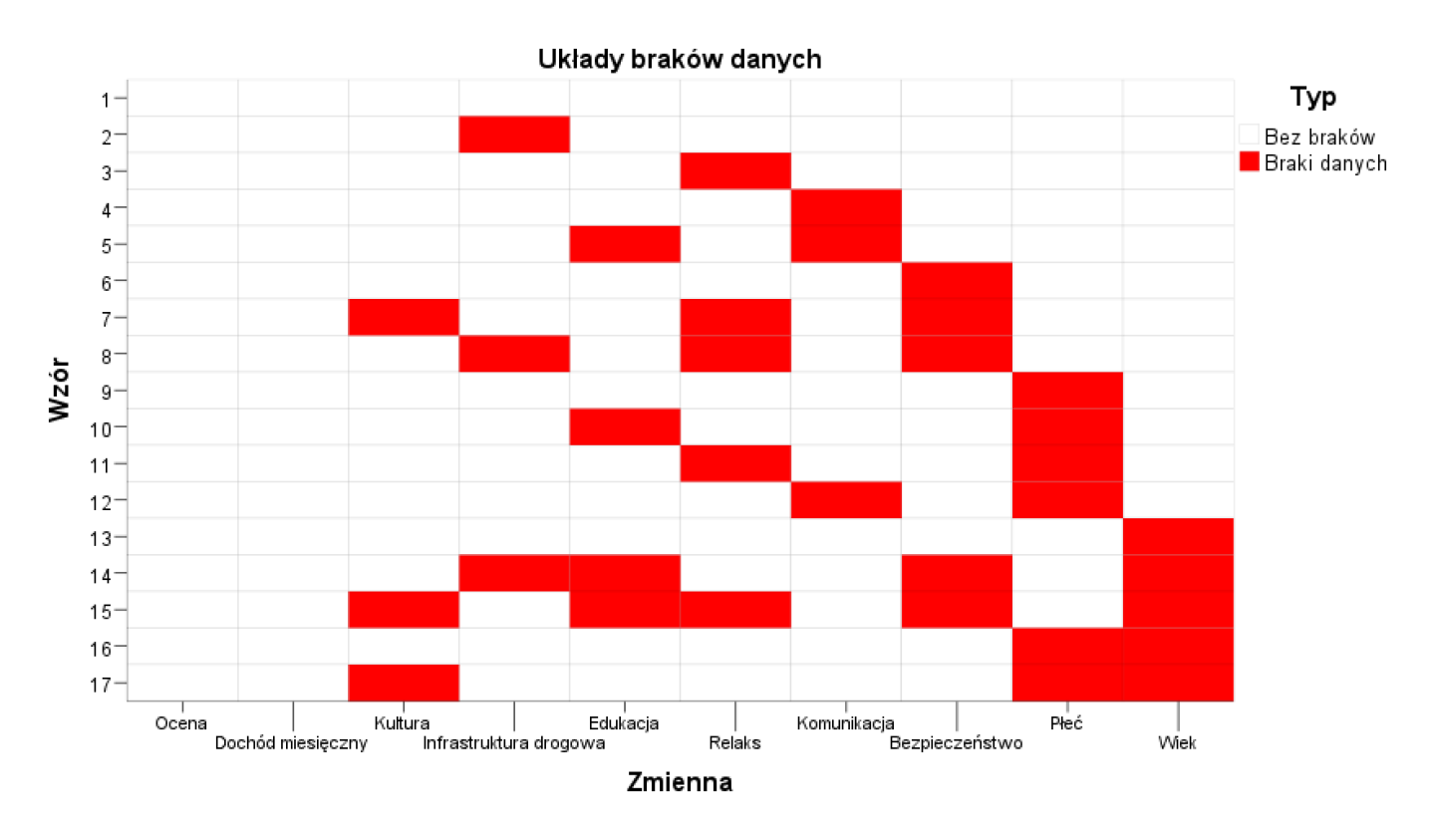
PS IMAGO PRO oferuje również w pełni automatyczny tryb imputacji wielokrotnej, który wybiera najbardziej odpowiednią metodę imputacji w oparciu o charakterystykę danych, pozostawiając jednocześnie użytkownikowi możliwość własnego dostosowania modelu.
Procedura ta generuje kilka możliwych wartości brakujących danych i tworzy kilka kompletnych zbiorów. Dla każdego z nich użytkownik otrzymuje podsumowanie wyników oraz jeden wynik mieszany (ze wszystkich stworzonych zbiorów).
Procedura Wielokrotne podstawienia, służąca do imputacji wielokrotnej, jest przydatna, gdy braki danych nie są całkowicie losowe oraz pozwala uzyskać:
- najdokładniejsze podstawienia braków danych dzięki imputacji wielokrotnej,
- automatyzacje procesu imputacji,
- wizualizację i diagnostykę układów braków danych, które pozwalają zrozumieć wzorce brakujących danych.
Wykorzystanie PS IMAGO PRO w zakresie radzenia sobie z brakami danych znacząco zwiększa dokładność analiz przy obecności niekompletnych informacji, automatyzując proces imputacji i zachowując kluczowe założenia statystyczne. Analiza braków oraz Wielokrotne podstawienia skracają czas przygotowania danych i ułatwiają ocenę jakości imputacji dzięki szczegółowym raportom. Takie podejście nie tylko ułatwia dokładne estymacje, ale także pomaga w jasnej interpretacji i efektywnej komunikacji wyników badań.
Podsumowanie
Braki danych są powszechnym problemem w ilościowej analizie danych. Mogą one potencjalnie prowadzić do zniekształcenia wyników i zmniejszenia wiarygodności wniosków. Do radzenia sobie z brakami stosuje się różne metody, od prostego usuwania obserwacji po bardziej złożone techniki imputacji, takie jak imputacja pojedyncza lub wielokrotna. Imputacja wielokrotna, wyróżniająca się możliwością generowania wielu potencjalnych zestawów danych z różnymi estymowanymi wartościami dla brakujących danych, pozwala na przeprowadzenie bardziej kompleksowej i wiarygodnej analizy. Wykorzystanie procedury wielokrotnych podstawień w PS IMAGO PRO pozwala analitykowi na automatyzację procesu imputacji, dostarczając szczegółowych raportów i diagnoz, które pomagają zrozumieć naturę i wzorce brakujących danych. Takie podejście nie tylko ułatwia obsługę braków danych, ale także zwiększa dokładność i wiarygodność przeprowadzanych analiz, co jest kluczowe dla osiągania rzetelnych i dokładnych wyników.
[1] Więcej o mocy testu: https://predictivesolutions.pl/moc-testu
[2]Więcej szczegółów na temat typów braków danych można znaleźć w: Schafer, J., Graham, J.: (2002). Missing data: Our view of the state of the art. Psychological Methods, 7, 147-177.