Węzeł Auto Przygotowanie umożliwia szybkie i proste przygotowanie danych do budowania modelu, bez ręcznego sprawdzania i analizowania poszczególnych zmiennych. W rezultacie budowa i ocena modeli będzie odbywać się szybciej, ale również wyniki takiego modelu mogą być lepsze w porównaniu do danych nieprzetworzonych. Ponadto korzystanie z automatycznego przygotowywania danych poprawia elastyczność procesów automatycznego modelowania, takich jak odświeżenie modelu w PS CLEMENTINE PRO.
Analityk może korzystać z węzła w sposób w pełni zautomatyzowany, pozwalając węzłowi wybrać i zastosować poprawki lub może wyświetlić podgląd proponowanych zmian przed ich wprowadzeniem i zaakceptować je, albo odrzucić zgodnie z potrzebami.
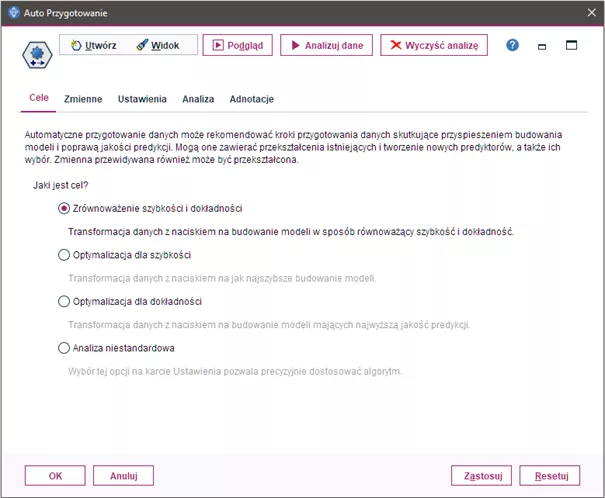
Rys. 1
Wybór jednego z celów przygotowania danych w węźle Auto Przygotowanie
Parametryzacja węzła Auto Przygotowanie
Po wybraniu jednego z celów warto przejść na kartę Zmienne. Pozwala ona na określenie, czy w procesie przygotowania danych mają być brane pod uwagę wstępnie zdefiniowane role dla zmiennych, czy też analityk chce użyć niestandardowych ról, które w tym oknie może określić. Po wybraniu tej opcji można wskazać, która zmienna będzie zmienną przewidywaną (opcjonalnie), a które zmienne mają być zmiennymi wejścia.
Przejdźmy do karty Ustawienia, na której możemy zdefiniować wiele ustawień związanych z wykluczeniem zmiennych, wyborem predyktorów oraz innymi ważnymi kwestiami.
Ustawienia zmiennych
Opcje dostępne tutaj pozwalają na użycie zmiennych ważących. W pierwszej opcji (Użyj zmiennej częstości) jest to zmienna wagi częstości. Tej opcji należy użyć, jeśli każdy rekord w danych uczących reprezentuje więcej niż jedną jednostkę, np. jeśli stosowane są dane zagregowane. Wartości zmiennych powinny odpowiadać liczbom jednostek reprezentowanych przez poszczególne rekordy.
Opcja Użyj zmiennej ważącej umożliwia natomiast wybranie zmiennej jako wagi obserwacji. Są one stosowane w celu uwzględniania różnic w wariancji między poziomami zmiennej wyjściowej.
Dodatkowo mamy również możliwość wskazania sposobu obsługi zmiennych, które są wyłączone z modelowania. Należy określić, czy zmienne wykluczone mają zostać odfiltrowane z danych, czy też mają być pomijane.
Ostatnia dostępna opcja pozwala określić działanie dla zmiennych wejściowych, które nie pokrywają się z poprzednią analizą. Należy określić, co stanie się, jeśli co najmniej jedna wymagana zmienna wejściowa będzie niedostępna w wejściowym zbiorze danych w czasie wykonywania węzła.
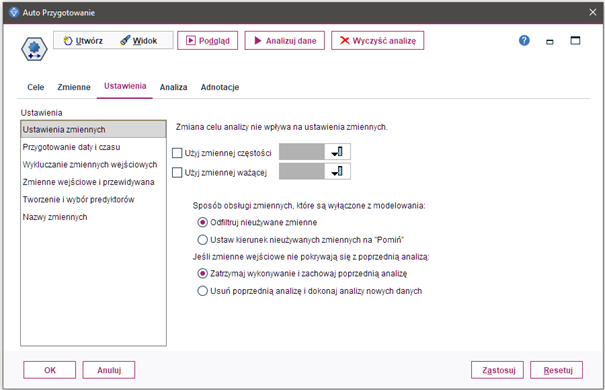
Rys. 2
Karta Ustawienia węzła Auto Przygotowanie
Przygotowanie daty i czasu
Wiele algorytmów modelowania nie potrafi bezpośrednio przetwarzać danych dotyczących dat i czasu. Te ustawienia pozwalają na wyznaczenie nowych danych czasu trwania, które mogą posłużyć jako dane wejściowe dla modelu, bazując na dostępnych w istniejących danych informacjach o dacie i czasie. Zmienne z datą i czasem muszą być wstępnie zdefiniowane z użyciem odpowiednich typów danych, takich jak data lub czas. Oryginalne zmienne związane z datą i czasem nie zostaną uwzględnione przez proces automatycznego przygotowywania danych jako dane wejściowe do modelu.
Dostępne opcje pozwalają wyliczyć czas, jaki upłynął od daty odniesienia, tj., ile lat, miesięcy i dni minęło od określonej daty odniesienia dla każdej zmiennej zawierającej daty oraz wyliczyć czas, jaki upłynął od czasu odniesienia (godziny, minuty lub sekundy).
Ponadto analityk może również wyodrębnić cykliczne elementy czasu. Te ustawienia umożliwiają rozdzielenie pojedynczej zmiennej, zawierającej datę lub czas, na kilka nowych zmiennych. Na przykład, jeśli zostaną wybrane wszystkie trzy opcje dla daty, dla zmiennej wejściowej np. „2024-09-23”, zostanie ona rozdzielona na trzy oddzielne zmienne: rok (2024), miesiąc (09) i dzień (23). Każda z nich zostanie opatrzona przedrostkiem, zdefiniowanym w opcjach Nazwy zmiennych.
Wykluczanie zmiennych wejściowych
Jakość danych jest kluczowym elementem, który wpływa na dokładność predykcji. Te opcje pozwalają określić parametry dla danych wejściowych do predykcji. Wszystkie zmienne, które są stałe lub mają 100% braków danych, zostają automatycznie wykluczone.
Pierwsza opcja umożliwia zdefiniowanie maksymalnego procentu braków danych (Wyklucz zmienne wejściowe o zbyt dużej liczbie braków). Zmienne, w których liczba braków danych przekracza określoną wartość procentową, zostają usunięte z dalszej analizy.
Kolejna opcja Wyklucz zmienne nominalne o zbyt dużej liczbie unikatowych kategorii pozwala na określenie liczby kategorii, powyżej której zmienne nominalne będą wykluczone z dalszej analizy. Ta opcja jest przydatna do automatycznego usuwania z modelowania zmiennych zawierających informacje unikalne dla rekordu, takie jak identyfikator, adres lub nazwa.
Ostatnia opcja, tj. Wyklucz zmienne kategorialne o zbyt dużej liczbie wartości w jednej kategorii, pozwala na określenie maksymalnego procentu, powyżej którego zmienne porządkowe i nominalne z kategorią, która zawiera więcej rekordów od określonej wartości procentowej, są usuwane z dalszej analizy. Domyślnie ta opcje jest wyłączona. Przykładem takiej zmiennej może być zmienna płeć, gdzie większość rekordów dotyczy jednej płci (np. 95% mężczyzn i 5% kobiet).
Przygotowywanie zmiennych wejściowych i przewidywanych
Opcje dotyczące przygotowania zmiennych wyjściowych i przewidywania są podzielone na dwie sekcje. Pierwsza sekcja to Dostosowanie typów i poprawa jakości danych. Dla zmiennych wejściowych oraz przewidywanych można zastosować różne transformacje, aby zachować integralność wartości zmiennych przewidywanych. Na przykład prognozowanie przychodu w złotówkach może mieć większy sens niż prognozowanie w formie logarytmu tego przychodu.
Jeżeli w zmiennej przewidywanej lub wejściowej występują brakujące dane, można określić, czy mają one być zastępowane, co pozwala na dalsze przetwarzanie tych zmiennych przez niektóre algorytmy, unikając utraty istotnych informacji. Dodatkowo analityk może również zaznaczyć opcję, która pozwala na identyfikowanie i korygowanie wartości odstających poprzez usunięcie tych wartości, bądź zastąpienie ich wartość odcięcia.
Druga sekcja to Transformacja zmiennej ilościowej. Opcje te pozwalają sprowadzić wszystkie zmienne ilościowe do wspólnej skali. Analityk ma do wyboru standaryzacje, normalizacje Min/Maks oraz transformacje Boxa-Coxa redukującą skośność.
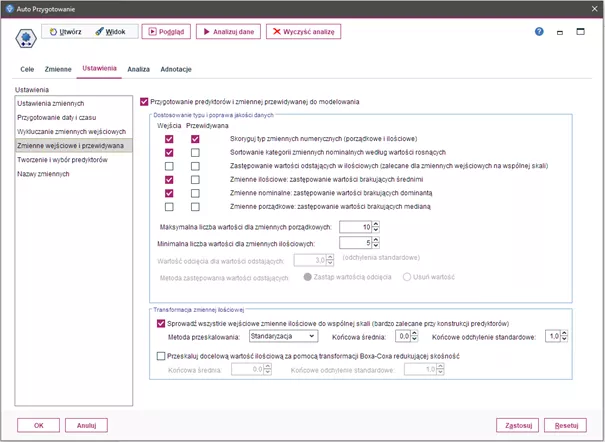
Rys. 3
Ustawienia opcji Zmienna wejścia i przewidywana dla węzła Auto Przygotowanie
Tworzenie i wybór predyktorów
Opcje tu dostępne są aktywne po włączeniu opcji Transformacja, tworzenie i wybór zmiennych wejściowych w celu poprawy jakości predykcji. Warto jednak pamiętać, że jeśli wartości na tej karcie zostaną zmienione, karta Cele zostanie automatycznie zaktualizowana, i zostanie wybrana opcja Analiza niestandardowa. Gdy analityk zdecyduje się na modyfikacje tych opcji, dostępne będą trzy sekcje: Zmienne wejściowe jakościowe, Zmienne wejściowe Ilościowe i Wybór i tworzenie predyktorów.
Pierwsza sekcja pozwala poprawić efektywność modelu przez łączenie kategorii z małą liczbą obserwacji. To sprawia, że model staje się prostszy, zmniejszając liczbę zmiennych do analizy. Domyślnie ustawiony jest poziom istotności 0,05 do określenia, które kategorie połączyć. Jeśli nie ma zmiennej, którą chcemy przewidywać, możemy łączyć małoliczne kategorie na podstawie ich liczby. Należy wtedy ustalić minimalny procent rekordów, który musi być spełniony, aby kategorie mogły zostać połączone; domyślnie wynosi on 10%.
Druga sekcja dotyczy przewidywanej zmiennej jakościowej. Opcje te pozwalają skategoryzować ilościowe dane wejściowe z silnymi powiązaniami w celu zwiększenia wydajności przetwarzania.
Ostatnia sekcja dotyczy wyboru i tworzenia predyktorów. Analityk może wybrać tę opcję, aby usunąć predyktory z niskim współczynnikiem korelacji. W razie konieczności należy zmienić domyślną wartość poziomu istotności wynoszącą 0,05. Ta opcja ma zastosowanie tylko do ilościowych zmiennych wejściowych, w których zmienna przewidywana jest ilościowa oraz do wejściowych zmiennych jakościowych.
Nazwy zmiennych
Aby łatwo zidentyfikować nowe oraz przekształcone predyktory, automatyczny proces przygotowania danych generuje i dodaje podstawowe nazwy, przedrostki lub przyrostki. Użytkownik może je zmienić, aby lepiej odpowiadały jego potrzebom oraz charakterystyce danych. Jeśli chcemy użyć innych etykiet, można to zrobić w węźle znajdującym się później w strumieniu.
Wyniki działania węzła Auto Przygotowanie
Gdy ustawienia automatycznego przygotowywania danych – w tym zmiany wprowadzone na kartach Cele, Zmienne i Ustawienia – są przygotowane, możemy uruchomić cały proces, klikając na przycisk „Analizuj dane”. Algorytm zastosuje wybrane ustawienia do danych wejściowych i wyświetli wyniki na karcie Analiza.
Znajdziemy na niej podsumowanie przetwarzania danych w postaci tabeli i wykresu oraz zalecenia dotyczące ewentualnych modyfikacji lub dodatkowych ulepszeń danych. Dodatkowo można również przeglądać oraz odrzucać wprowadzone zmiany i np. użyć do modelowania danych niezmienionych.
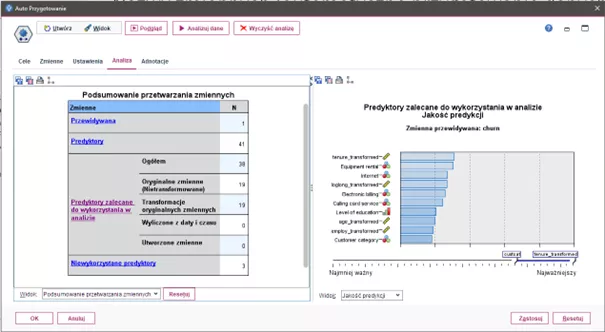
Rys. 4
Karta Analiza węzła Auto Przygotowanie prezentuje w podstawowym widoku najważniejsze informacje dotyczące przygotowanie danych do analizy
Węzeł Auto Przygotowanie wykorzystano w PS CLEMENTINE PRO do analizy Churn. Krótko mówiąc, Churn to wskaźnik odejścia klientów, który mierzy, ile osób rezygnuje z usług firmy w określonym czasie. Do analizy Churnu wykorzystano w tym przypadku regresję logistyczną, która określa prawdopodobieństwo odejścia klienta na podstawie różnych zmiennych.
Regresja logistyczna, dzięki swojej zdolności do modelowania zmiennych binarnych, jest idealnym narzędziem do przewidywania czy klient odejdzie, czy zostanie. Jak widać na rysunku 5, regresja logistyczna została wykonana na danych przetworzonych za pomocą węzła Auto Przygotowanie i bez przetwarzania.
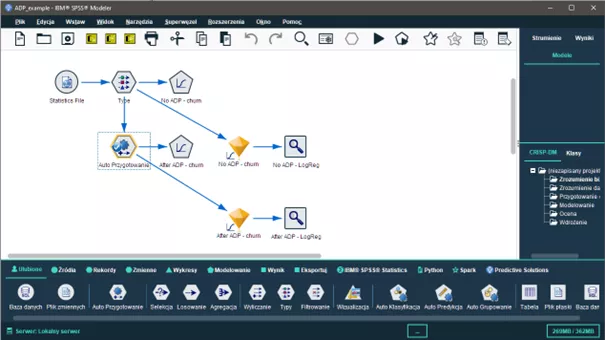
Rys. 5
Strumień analityczny, w którym do analizy Churn wykorzystano węzeł Auto Przygotowanie
Przyglądając się wynikom, można zauważyć, że model regresji logistycznej, do której wykorzystano dane z węzła Auto Przygotowanie, jest lepszy niż regresji wykonanej na danych bez przetwarzania. Procent poprawnej klasyfikacji klientów jest bliski 80% w modelu, w którym wykorzystano węzeł Auto Przygotowania.
|
Wyniki klasyfikacji regresji logistycznej |
Model bazujący na danych nieprzetworzonych |
Model bazujący na danych z węzła Auto Przygotowanie |
|---|---|---|
|
Poprawne |
10,6% |
78,8% |
|
Niepoprawne |
89,4% |
21,2% |
|
Ogółem |
100% |
100% |
Tabela 1. Porównanie wyników regresji logistycznej wykonaj na danych przetworzonych i nieprzetworzonych
Podsumowanie
Węzeł Auto Przygotowanie w PS CLEMENTINE PRO ma kluczowe znaczenie w procesie analizy danych, ponieważ automatyzuje i upraszcza przygotowanie zbioru danych do modelowania. Etap ten bywa czasochłonny i podatny na błędy, zwłaszcza gdy analityk musi ręcznie sprawdzać każdą zmienną. Auto Przygotowanie przyspiesza ten proces, automatycznie identyfikując problemy, takie jak brakujące dane, wartości odstające czy zmienne o zbyt wielu unikalnych wartościach, które mogą negatywnie wpłynąć na jakość modelu.
Węzeł umożliwia automatyczną transformację zmiennych ilościowych i jakościowych, standaryzację, usuwanie problematycznych zmiennych oraz tworzenie nowych, optymalnych predyktorów. Dzięki temu automatyzacja przygotowania danych zapewnia lepszą jakość predykcji, optymalizując proces budowania modeli. W porównaniu z danymi surowymi, dane przetworzone przez ten węzeł często skutkują lepszymi wynikami analizy, co pokazano na przykładzie analizy Churnu, gdzie automatyczne przetwarzanie poprawiło dokładność modelu predykcyjnego.