Modele statystyczne można podzielić na dwie główne kategorie: nadzorowane (supervised) oraz nienadzorowane (unsupervised). Modele nadzorowane to typ modelowania statystycznego, wykorzystujący dane wejściowe do przewidywania określonych wyników, takich jak wartość zmiennej wyjściowej.
Przykłady technik statystycznych wykorzystywanych w modelowaniu nadzorowanym obejmują m.in. drzewa decyzyjne C&RT, QUEST, CHAID, różne formy regresji (liniową, logistyczną, uogólnioną liniową czy regresję Coxa), sieci neuronowe, algorytmy SVM oraz sieci Bayesowskie. Te modele są szczególnie pomocne w przewidywaniu określonych wyników, takich jak decyzja o rezygnacji z zakupu lub identyfikacja transakcji noszącej znamiona oszustwa.
Aby łatwiej było to zrozumieć, przyjrzyjmy się przykładowi. Analityk danych, przystępując do pracy nad nowym zbiorem danych, na podstawie którego ma za zadanie rozwiązać konkretny problem biznesowy – np. rezygnacja z przedłużenia umowy dot. świadczonych usług. W tym celu chce zbudować model klasyfikacyjny, który będzie przyporządkowywał poszczególnych klientów do kategorii „przedłuży umowę” lub „zrezygnuje”. Oprócz odpowiedniego sprawdzenia i przygotowania danych do pracy analityk staje przed wyzwaniem, jaki typ modelu do tego zadania wybrać i który będzie najlepszy.
W celu ułatwiania wyboru odpowiedniego modelu można skorzystać z węzła Auto Klasyfikacja w PS CLEMENTINE PRO, który umożliwia tworzenie i porównywanie różnych modeli pod kątem klasyfikacji. Analityk może wybrać optymalną metodę analizy spośród dostępnych algorytmów modelowania. Węzeł ten generuje zestaw modeli na podstawie określonych opcji, a następnie tworzy ranking według wybranych kryteriów, co ułatwia podjęcie trafnych decyzji analitycznych.
Parametryzacja modeli do porównania
Co oferuje węzeł Auto Klasyfikacji i do czego służą poszczególne opcje? Na początek analityk w węźle Auto Klasyfikacja może w karcie Zmienne dostosować, jakie zmienne mają być użyte do generowania modeli. Domyślnie wybrana opcja użyje wstępnie zdefiniowanych ról zmiennych. Użytkownik może również samodzielnie przypisać zmienne, określając, które są zmienną przewidywaną, a które zmienne to predyktory.
Następnie, karta Model pozwala na zdefiniowanie, ile modeli ma zostać wygenerowanych w procesie analizy. Analityk może również określić kryteria, na podstawie których modele będą porównywane, co umożliwia wybór najbardziej adekwatnych metod do rozwiązania danego problemu.
Nazwa modelu – możliwość automatycznego wygenerowania nazwy modelu, która będzie bazować na zmiennej przewidywanej lub identyfikacyjnej. Jeśli takie zmienne nie są określone, nazwa może być oparta na typie modelu. Użytkownik ma także opcję nadania modelowi własnej, niestandardowej nazwy, co ułatwia organizację i identyfikację wyników.
Użyj danych podzielonych na podzbiory – jeśli w danych została zdefiniowana zmienna dzieląca na podzbiory, ta opcja pozwala na budowanie modelu wyłącznie na podstawie danych z podzbioru uczącego. Dzięki temu model może być bardziej precyzyjny, ponieważ jest trenowany na wyselekcjonowanej grupie danych.
Sprawdź krzyżowo – walidacja krzyżowa dostarcza modelowi zestaw danych, na których model jest trenowany (zbiór treningowy), oraz zestaw danych nowych, nieznanych wcześniej modelowi, na których jest on testowany (zbiór testowy lub walidacyjny). Głównym celem tej metody jest ocena zdolności modelu do przewidywania wyników dla nowych danych, które nie były uwzględnione w trakcie jego budowy, co pozwala na zidentyfikowanie problemów takich jak przeuczenie modelu. Analityk może wybrać liczbę tworzonych podzbiorów oraz dla zachowania powtarzalności przypisania podzbiorów jest możliwość ustawienie wartości startowej dla losowania.
Zbuduj modele dla każdego podziału – ta funkcja umożliwia tworzenie osobnych modeli dla każdej wartości zmiennych wejściowych, które zostały określone jako zmienne podziału. Jest to szczególnie przydatne w sytuacjach, gdy różne segmenty danych wymagają różnych podejść modelowania.
Ranguj modele według – opcja ta pozwala określić kryteria, które będą stosowane do porównywania i rangowania modeli. Do wyboru są m.in. ogólna dokładność, pole pod krzywą ROC, zysk, wzrost oraz liczba zmiennych. Warto zauważyć, że wszystkie te miary będą dostępne w raporcie podsumowującym, niezależnie od tego, które z nich zostały wybrane jako główne kryteria.
Rangowanie modeli – analityk może określić, na jakim zestawie danych mają bazować rangi modeli: na zbiorze uczącym czy na zbiorze testowym. Jest to szczególnie przydatne w przypadku pracy z dużymi zbiorami danych, gdzie użycie podzbioru danych do wstępnego monitorowania modeli może znacząco zwiększyć wydajność procesu modelowania. Takie podejście pozwala szybciej zidentyfikować najbardziej obiecujące modele.
Liczba modeli do uwzględnienia – pozwala na ustalenie maksymalnej liczby modeli, które zostaną uwzględnione w końcowym modelu użytkowym wygenerowanym przez węzeł. Modele są rangowane zgodnie z wcześniej określonymi kryteriami i najwyżej ocenione modele są automatycznie wybierane. Należy jednak pamiętać, że zwiększenie liczby uwzględnianych modeli może spowolnić działanie programu, a maksymalna dozwolona liczba modeli to 100.
Obliczanie ważności predyktora – w przypadku modeli, które oferują miarę ważności predyktorów, użytkownik może wyświetlić tabelę przedstawiającą względną ważność każdego z nich w procesie budowania modelu. Ważność predyktorów jest kluczowa, gdyż pozwala skupić się na najbardziej istotnych zmiennych i pominąć te mniej istotne, co może prowadzić do uproszczenia modelu. Należy jednak zauważyć, że obliczanie ważności predyktorów może wydłużyć czas potrzebny na przetworzenie modeli. Jest to więc zalecane, gdy analiza skupia się na mniejszej liczbie modeli, które wymagają dokładniejszej analizy.
Kryteria zysku – te opcje pozwalają na bardziej szczegółowe i realistyczne modelowanie działań związanych z klientami, uwzględniając zarówno koszty, jak i potencjalne zyski, co pomaga lepiej przewidzieć opłacalność różnych działań marketingowych czy sprzedażowych. Koszty są liczone dla każdego klienta. Jeśli dana akcja nie zakończy się sukcesem, nie jest dla tego klienta liczony przychód, a jedynie koszty.
- Koszty – opcja ta pozwala określić, jakie koszty wiążą się z daną akcją. Mogą być stałe (taki sam dla każdego przypadku) lub zmienne (różny w zależności od rekordu). Na przykład koszt wysłania oferty do klienta można ustalić jako stałą wartość albo określić go na podstawie jakiejś zmiennej, np. na podstawie historii wcześniejszych interakcji z klientem.
- Przychód – w tym przypadku można określić zysk, jeśli akcja zakończy się sukcesem. Przychód również może być stały lub zmienny. Dzięki temu można przewidzieć zysk, jeśli uda się przekonać klienta do skorzystania np. z oferty.
- Waga – jeżeli dane, które są analizowane, reprezentują więcej niż jednego klienta, można użyć wag, aby odpowiednio dostosować wyniki. Można ustawić stałe wagi dla każdego rekordu lub wagi zmienne, zależne od liczby klientów w danym rekordzie.
Kryteria wzrostu – opcja dostępna tylko dla zmiennych przewidywanych typu flaga (czyli takich, które mają dwie możliwe wartości, na przykład "tak" lub "nie"). Pozwala ona określić procent danych (percentyl), które będą brane pod uwagę przy obliczaniu wzrostu, czyli tego, jak dobrze model radzi sobie z przewidywaniem. Załóżmy, że analityk tworzy model, który przewiduje, czy klient przedłuży umowę. Można użyć kryterium wzrostu, aby skupić się na górnych 10% klientów, którzy są najbardziej skłonni do przedłużenia umowy. To pomoże lepiej ocenić, jak skuteczny jest model w przewidywaniu zachowań tej kluczowej grupy klientów.
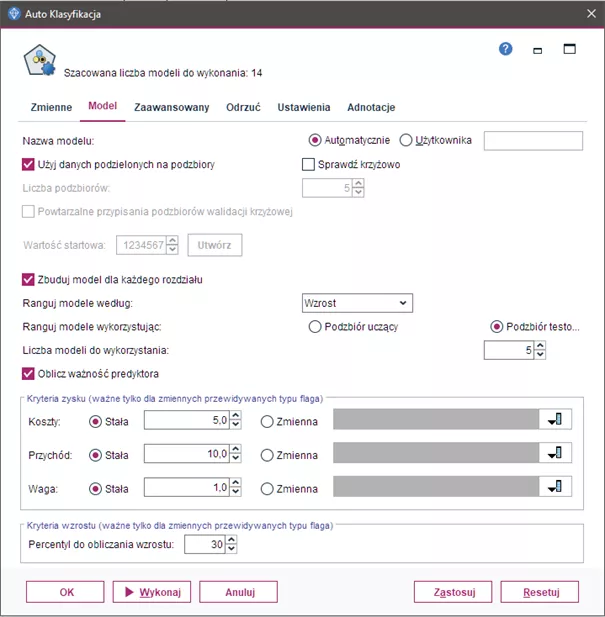
Rysunek 1.
Okno węzła Auto Klasyfikacji z możliwością parametryzacji tworzonych modeli do porównania
Wybór modeli do porównania
Karta Zaawansowane umożliwia wybór konkretnych modeli, które mają być używane. Pozwala na zaznaczenie typów modeli (algorytmów) do uwzględnienia w porównaniu. Wybranie większej liczby typów modeli zwiększa liczbę generowanych modeli oraz czas przetwarzania. Dla każdego algorytmu można użyć ustawień domyślnych lub samodzielnie określić opcje, umożliwiając porównanie wielu modeli w jednym przebiegu. Maksymalnie może być wybranych 17 różnych typów modeli do porównania. Dodatkowo opcja Ogranicz maksymalny czas na budowanie jednego modelu, pozwala na ustawienie limitu czasu na budowę jednego modelu dla wybranych typów algorytmów. W ten sposób zapobiega opóźnieniom w przypadku skomplikowanych modeli.
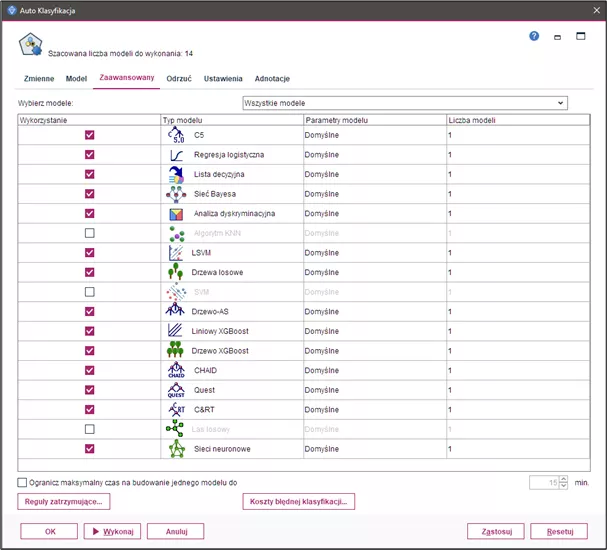
Rysunek 2.
Karta Zaawansowana pozwala na wybór typu modeli do porównania
Odrzucanie modeli niespełniających wymogów
Karta Odrzuć – Auto Klasyfikacja umożliwia automatyczne odrzucanie modeli, które nie spełniają określonych kryteriów. Modele te nie będą wymienione w raporcie podsumowującym.
Można określić próg minimalnej dokładności ogólnej i próg maksymalnej liczby zmiennych używanych w modelu. Ponadto dla zmiennych przewidywanych typu flaga można określić próg minimalnego wzrostu, zysku i obszaru pod krzywą ROC; wzrost i zysk określane są tak, jak określono to na karcie Model.
Opcjonalnie można skonfigurować węzeł tak, by wykonywanie było zatrzymywane po wygenerowaniu pierwszego modelu spełniającego wszystkie określone kryteria.
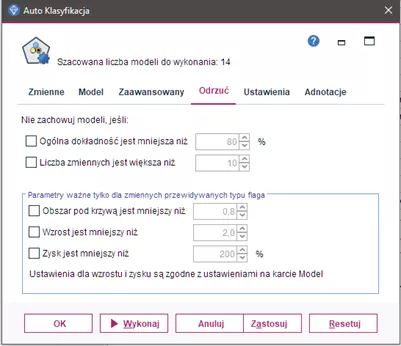
Rysunek 3.
Opcje karty Odrzuć, które pozwalają określić kryteria odrzucenia modeli, które nie spełniają wymagań analityka
Wyniki dla węzła Auto Klasyfikacja
Przyjrzyjmy się rezultatom działania węzła Auto Klasyfikacji. Na rysunku 4 zaprezentowano strumień analityczny przygotowany w PS CLEMENTINE PRO, w którym zdefiniowano plik danych oraz kilka podstawowych ustawień. Następnie w węźle Auto Klasyfikacja wprowadzono ustawienia dotyczące wyboru modeli, kosztów oraz zbiorów testowych i uczących. Po wprowadzeniu zmian uruchomiony został cały strumień.
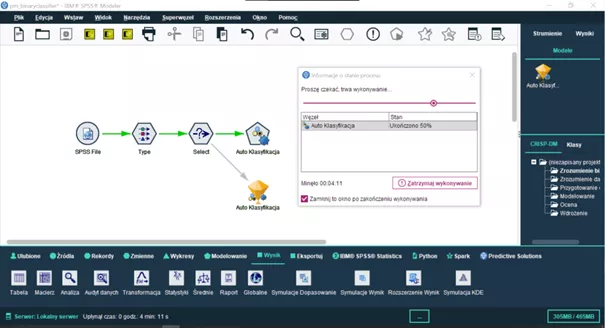
Rysunek 4.
Przykładowy strumień analityczny z uruchomionym węzłem Auto Klasyfikacji
Rezultatem działania jest węzeł typu Model. Po kliknięciu otrzymamy podsumowanie o przygotowanych modelach, możemy je sortować według kryteriów, które są dla nas istotne. Ponadto dla każdego typu modelu analityk może przejrzeć szczegóły dotyczące używanych zmiennych, ważności predyktorów, czy też inne dodatkowe informacje. Warto zaznaczyć, że dla każdego z typów modeli podgląd szczegółów jest inny, np. może on zawierać drzewo klasyfikacyjne lub diagram sieci neuronowej. Na karcie Podsumowanie znajdują się szczegółowe informacje na temat wykonania procedury oraz dla każdego z utworzonych modeli.
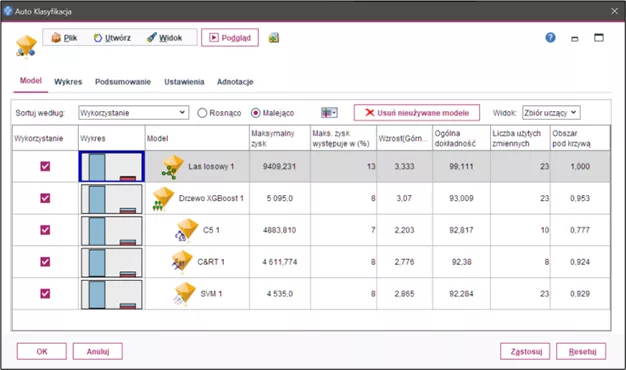
Rysunek 5.
Rezultat działania węzła Auto Klasyfikacja prezentujący podsumowanie dla 5 modeli, które osiągnęły najlepszy wynik
Podsumowanie
Węzeł Auto Klasyfikacja w PS CLEMENTINE PRO to użyteczne narzędzie, które znacząco przyspiesza i ułatwia pracę z danymi. Dzięki temu węzłowi można automatycznie tworzyć i porównywać różne modele predykcyjne, co pozwala na szybkie znalezienie najlepszego rozwiązania dla danego problemu. Auto Klasyfikacja automatyzuje proces wyboru algorytmów, parametrów i kryteriów oceny, co oszczędza czas i redukuje ryzyko popełnienia błędów. W rezultacie, analitycy mogą skupić się na interpretacji wyników i podejmowaniu decyzji, zamiast na ręcznym tworzeniu i testowaniu wielu różnych modeli.