Coraz częściej przedmiotem analizy danych staje się tekst. W wielu przedsiębiorstwach czy też instytucjach dane przechowywane są także w formie tekstowej, co z jednej strony umożliwia wprowadzanie dodatkowych informacji, z drugiej jednak utrudnia ich późniejsze przekształcenie na formę wygodną z punktu widzenia oprogramowania statystycznego. Oprócz informacji wewnętrznych, wykorzystywanych w bieżącym działaniu przedsiębiorstwa, bezcennym źródłem wiedzy w kształtowaniu produktów i usług są opinie konsumentów, tradycyjnie zbierane za pomocą badań i formularzy, ale również za pośrednictwem wpisów na forach lub w mediach społecznościowych.
Tekst, który może stać się przedmiotem analizy, jest oczywiście także wynikiem badań ankietowych. W ankietach oprócz pytań zamkniętych, w których to respondent ma za zadanie na postawione pytanie wybrać jedną lub więcej odpowiedzi, pojawią się również pytania półotwarte lub otwarte. W przypadku badań, które stawiają sobie za cel eksplorację, poznanie jakiegoś obszaru badawczego, który wcześniej był słabo opisany, badacz może zadać respondentowi pytanie otwarte, licząc na jego własną odpowiedź. Innym przykładem, gdzie badacz zada pytanie otwarte jest chęć poznania opinii badanych na temat produktu lub usługi. Oczywiście badany może wyrazić opinie na skali od „Zdecydowanie zadowolony” do „Zdecydowanie niezadowolony”, ale w przypadku odpowiedzi negatywnych ważne jest poznanie, jakie były przyczyny tego niezadowolenia tak, aby można było wprowadzić zmiany i poprawić działanie produktów lub świadczonych usług.
Zazwyczaj jakość danych tekstowych, które poddajemy analizie, pozostawia wiele do życzenia. Jeżeli dane przechowywane są w formie tekstowej zamiast kodowanych liczbowo kategorii, to nierzadko kosmetyczne zmiany w formularzu skutkują nowymi kategoriami pojawiającymi się w danych. Z drugiej strony opinie klientów, które są zbierane na podstawie komentarzy, zawierają ogromną ilość ciekawych informacji, ale w ich przypadku poważnym problemem jest brak kontroli zawartości, poza podstawową korektą błędów.
Podstawowym problemem podczas analizy opinii i pytań otwartych jest to, że odpowiedzi mogą mieć właściwie dowolną formę, składnię czy ortografię, a respondenci posługują się różnymi konwencjami, chociażby podczas wyrażania emocji - zaczynając od emotikonek, poprzez wykorzystanie wielkich liter, a kończąc na zwielokrotnionych wykrzyknikach czy znakach zapytania.
Dane tekstowe mogą być również zanieczyszczone z przyczyn technicznych. Dane pozyskiwane ze stron internetowych, forów, czy mediów społecznościowych często pełne są dodatkowych znaczników oraz zbędnych elementów, które sprawiają, że tekst wygląda efektownie w przeglądarce internetowej, jednak podczas analizy ich obecność przysparza wielu problemów. Ważną kwestią są problemy z kodowaniem, czy formatowaniem, które często występują w przypadku pozyskiwania tekstu z hurtowni danych. Osobnym tematem są informacje nadmiarowe – numery telefonów w tekście opinii, wartość transakcji, numer faktury, dane adresowe czy nawet pesel, które teoretycznie nie powinny się znaleźć w zbiorze danych, a jednak bardzo często się w nim znajdują.
Możliwości czyszczenia tekstu w PS IMAGO PRO
Jak widać, bardzo często przed przystąpieniem do analizy tekst powinien zostać oczyszczony z nadmiarowych lub niepoprawnych informacji, a jego zawartość powinna zostać maksymalnie ujednolicona (wielkość liter, znaki diakrytyczne). Na tym etapie sprawdzi się procedura Wyczyść tekst, która zawiera funkcje, umożliwiające przekształcenia, wyczyszczenie i dostosowanie zmiennych tekstowych według podanych przez użytkownika kryteriów. Procedura pozwala na:
- modyfikację białych znaków,
- zamianę i usuwanie znaków diakrytycznych dla słowników: polskiego, niemieckiego, węgierskiego, włoskiego, hiszpańskiego, słowackiego, czeskiego,
- korygowanie wielkości liter,
- usuwanie zwielokrotnionych znaków,
- usuwanie bądź zamianę zestawu znaków,
- usuwanie bądź zamianę tekstu pomiędzy znakami,
- usuwanie bądź zamianę grupy znaków (np. tylko liczb, tylko znaków interpunkcyjnych).
Co istotne, możliwe jest jednoczesne wykonanie kilku operacji na danych. W tym jednak przypadku trzeba uwzględnić kolejność wykonywanych operacji. Zaznaczenie wszystkich opcji spowoduje wykonanie się działania w ustalonej z góry kolejności: znaki diakrytyczne, wielkości liter, białe znaki, pomiędzy znakami, zestaw znaków, grupy znaków, usuń zwielokrotnione znaki.
W tym przykładzie posłużę się danymi zawierającymi opinie klientów jednej z sieci hotelowych. Poniżej fragment danych, które poddamy procesowi czyszczenia.
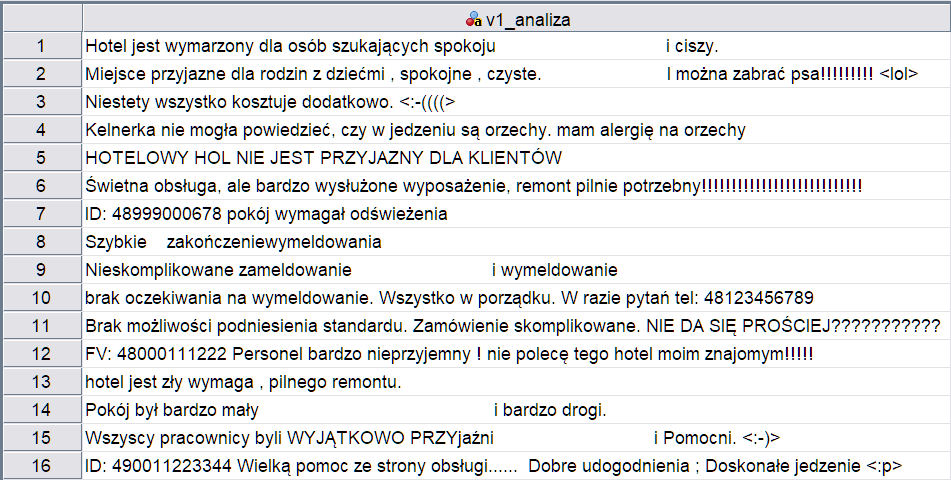
Rysunek 1. Fragment danych tekstowych przed przekształceniem
Jak widzimy, praca na zmiennej w takiej postaci będzie utrudniona, ze względu na sposób zapisu niektórych wypowiedzi oraz dodatkowe znaki znajdujące się w wypowiedziach badanych. Korzystając z procedury chcemy usunąć lub przekształcić tekst tak, aby:
- usunąć nadmiarowe białe znaki (spacje),
- zamienić wypowiedzi zapisane wielkimi literami na małe litery,
- usunąć dane typu id, numer telefonu, numer rachunku itp.,
- wyczyścić tekst z emotikonek.
Konfiguracja ustawień Wyczyść tekst w PS IMAGO PRO
Procedura dostępna jest w zakładce Predictive Solutions -> Transformacje -> Wyczyść tekst. W oknie kreatora w pierwszej kolejności należy wskazać zmienną, którą zamierzamy oczyścić. Jako, że rezultatem działania tej procedury będzie nowa zmienna, zawierająca już oczyszczone dane, należy również wskazać nazwę nowej zmiennej.
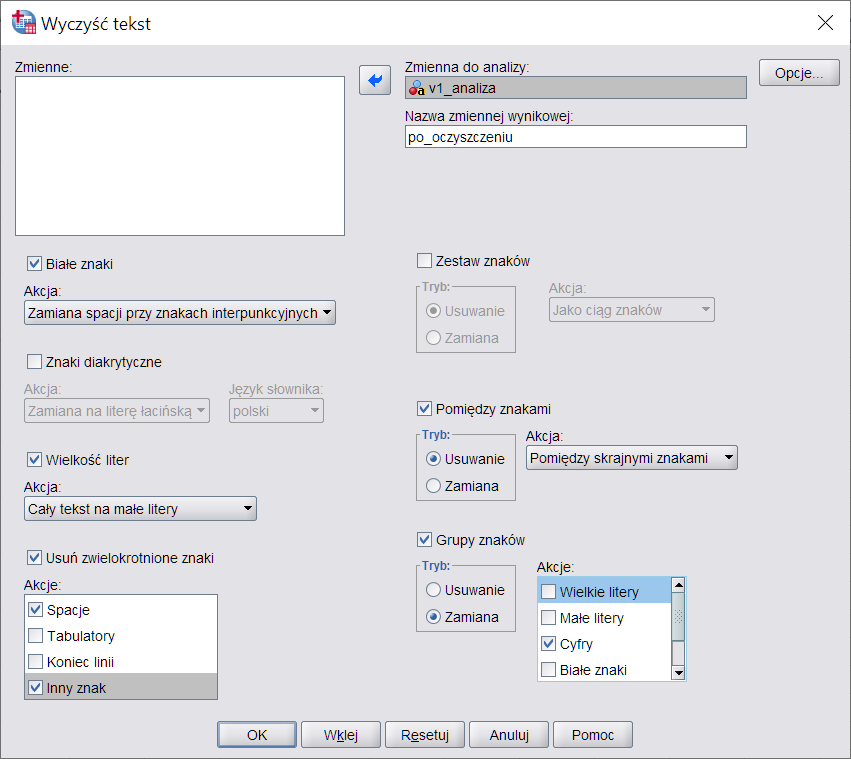
Rysunek 2. Okno procedury Wyczyść tekst
Jak widać w danych są wypowiedzi, w których przed znakiem przecinka pojawiały się spacje. Aby rozwiązać ten problem pozostawiamy domyślnie zaznaczony checkbox Białe znaki i wybieramy z listy opcję Zamień spacje przy znakach interpunkcyjnych. Jest to przydatna funkcja, szczególnie, jeśli w późniejszej pracy z danymi chcemy dzielić automatycznie tekst po znaku przecinka, a pojawienie się odstępu przed takim znakiem utrudniłoby nam to zadanie. Często podczas prezentacji wyników badań odbiorca oczekuje przykładowych wypowiedzi respondentów na jakiś temat – wówczas ta funkcjonalność również pozwala szybko oczyścić tekst z ewidentnych błędów gramatycznych.
Przykład:

W przypadku niektórych wypowiedzi (szczególnie tych negatywnych) można zauważyć, że klienci zapisywali swoje opinie wielkimi literami, dlatego też w kolejnym kroku zaznaczamy opcję Wielkość liter oraz zostawiamy wybraną opcję Cały tekst na małe litery. Takie przekształcenie jest nie tylko odpowiedzią na potrzebę estetycznej prezentacji tekstu. Ujednolicenie sposobu zapisu jest kluczowe przed przystąpieniem do analizy polegającej na zliczaniu wystąpienia słów (np. określeń produktu). Słowo zapisane wielkimi literami będzie innym słowem (inny zestaw znaków) niż to samo słowo zapisane za pomocą małych liter.
Przykład:

Kolejna funkcjonalności pozwala nam usunąć zwielokrotnione znaki. Należy zaznaczyć pole Usuń zwielokrotnione znaki. Domyślnie zaznaczone na liście są Spacje, dodatkowo zaznaczmy Inny znak, następnie w Opcjach w polu Usuń zwielokrotnione znaki wpiszmy znaki ?!.
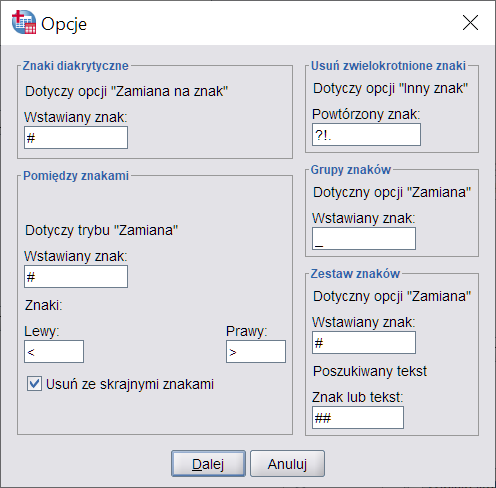
Rysunek 3. Dodatkowe opcje procedury Wyczyść tekst
Jest to szczególnie ważne w sytuacji, gdy analityk chce obliczać podobieństwo dwóch ciągów tekstowych, natomiast wielokrotne występowanie chociażby dodatkowych spacji może tą analizę utrudnić. W przypadku naszej próbki wypowiedzi klienci często podkreślali swoje emocje stosując zwielokrotnione wykrzykniki albo znaki zapytania. Zwielokrotnione spacje mogą być rezultatem formatowania tekstu, jeżeli edytor komentarzy nie udostępniał takich funkcjonalności.
Przykład:

Bardzo często w tekście pobieranym ze źródeł internetowych (choć nie tylko) znajdują się różnego rodzaju znaczniki html służące formatowaniu tekstu, są one zapisane w ostrych nawiasach <>. Nierzadko również emotikonki i inne dodatkowe grafiki kodowane są w tekście specyficznymi znakami – możemy się z nimi spotkać np. otrzymując smsa z ikonką niewspieraną przez system operacyjny naszego smartfona. Usunięcie ich lub pozostawienie zależy w dużej mierze od podejścia badacza – może on uznać, że tego rodzaju znaki są istotne w analizie całej wypowiedzi. Na potrzeby tego przykładu usuniemy je zaznaczając opcje Pomiędzy znakami i wybierając akcję Pomiędzy skrajnymi znakami oraz pozostawiając włączony tryb Usuwanie. Aby zdefiniować znaki graniczne musimy przejść do Opcji, a następnie w polu Lewy oraz Prawy wpisujemy odpowiednio znaki < >. Pamiętajmy o tym, aby checkbox Usuń ze skrajnymi znakami był zaznaczony. Dzięki temu procedura usunie również wskazane znaki.
Przykład:

Cyfry zamieszczone w tekście komentarza mogą budzić pewne podejrzenia. Tak jak wcześniej zostało to wspomniane, w niektórych odpowiedziach pojawiają informacje o ID klienta, numerach telefonów lub faktur. Zazwyczaj nie chcemy prezentować takich informacji a i z punktu widzenia analizy treści tekstu nie są one przydatne. Aby zanonimizować te informacje zamienimy wszystkie cyfry w przekształcanej zmiennej na inny znak, którym będzie gwiazdka. Dzięki temu zachowamy informacje o występowaniu cyfr w tekście, ale nie będą one widoczne podczas prezentacji. W tym celu użyjemy opcji Grupa znaków, która pozwala zamienić lub usunąć wszystkie znaki ze wskazanej grupy. W tym celu odznaczamy w polu akcji Wielkie litery i zaznaczamy checkbox Cyfry. Zmieniamy również tryb Usuwanie na Zamiana, a następnie klikamy na Opcje. W obszarze Grupa znaków wpisujmy gwiazdkę i klikamy Dalej.
Przykład:

Gdy ustawimy już wszystkie funkcje, jakie chcemy zastosować do zmiennej tekstowej i wykonamy procedurę, otrzymamy nową zmienną. Jaka widać na poniższym zrzucie tekst wygląda już znacznie lepiej. Nie ma już powtórzonych znaków, nadmiarowych spacji, czy też tekstu zapisanego wielkimi literami.
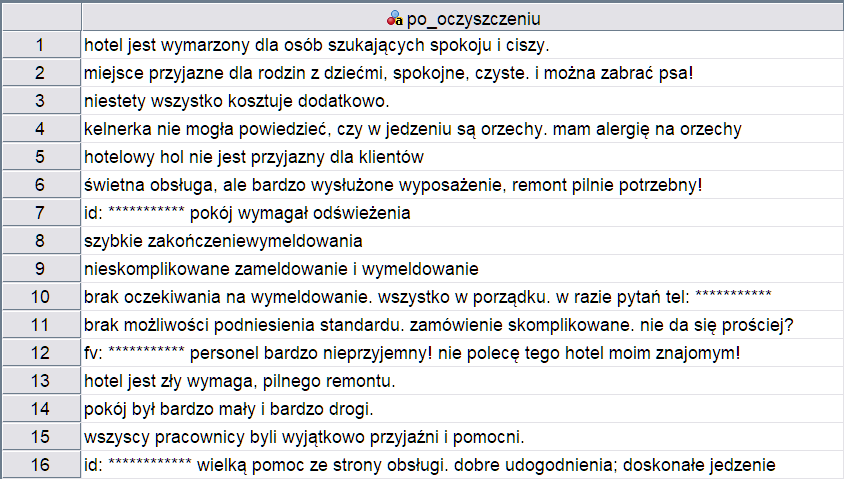
Rysunek 4. Dane tekstowe po wykonaniu procedury Wyczyść tekst
Podsumowanie
Podsumowując, pracując z danymi tekstowymi, czy to zebranymi z badań ankietowych czy też pochodzącymi z innych źródeł, często otrzymujemy dane, które będą wymagały odpowiedniego przygotowania, aby można było później przystąpić do ich analizy. Jest to szczególnie istotne nie tylko w przypadku kodowania pytań otwartych, ale również w przypadku gdy analityk np. chce ocenić na ile dwa ciągi znaków (analizowane teksty) są do siebie podobne. Zaniedbania popełnione na tym etapie niestety mogą w konsekwencji prowadzić do trudności w interpretacji wyników, a nawet do błędów popełnionych podczas analizy. Procedura Wyczyść tekst daje użytkownikowi możliwość skorzystania z kilku funkcjonalności jednocześnie i pozwala szybko przekształcić oraz oczyścić tekst z niepotrzebnych znaków.