Parę słów na początek
Mówiąc o analizie danych, mamy zazwyczaj na myśli dane zorganizowane w układzie wierszowo-kolumnowym, nadające się do klasycznych analiz statystycznych lub Data Mining. Wiemy też, że zawężając się do nich, dużo tracimy, bo wiele cennych informacji ukrytych jest w danych tekstowych. Danych, które są wszechobecne i występują w postaci pól tekstowych w repozytoriach oraz w plikach o różnych formatach. W takiej formie może być zapisana korespondencja mailowa, artykuły, komentarze pod nimi, posty na forach internetowych, oficjalne dokumenty firmowe itp. Lista potencjalnych źródeł danych tekstowych jest bardzo długa. Także wolumen tego typu danych często jest ogromny.
Chcesz dowiedzieć się więcej o data mining?
Zapraszamy na szkolenie DM 1. Metodyka projektów, przygotowanie danych i wprowadzenie do modelowania
Zasadniczym pytaniem jest więc pytanie o to, czy potrafimy z takich danych wydobyć istotne informacje? Terminem, który często pojawia się jako odpowiedź na to pytanie, jest Text Mining. Czym jest Text Mining i czy da się go użyć do analizy polskich tekstów? Są to pytania, których dotyczy ten artykuł. Oczywiście, nie jest możliwe w krótkim artykule wyjaśnienie wszelakich niuansów związanych z zagadnieniem Text Miningu. Mam jednak nadzieję, że uda się ten temat choć trochę przybliżyć. Dla ułatwienia i ustrukturyzowania dalszych wywodów podzielmy naszą „wycieczkę” po Text Miningu na pięć etapów, a będą to:

Rysunek 1. 5 etapów text mining
Przygotowanie danych i sprawdzanie poprawności
Pierwszym krokiem jest wybór danych, które będą przedmiotem naszej analizy. Tutaj musimy zdecydować jakiego typu danych chcemy użyć, z jakiego okresu itp. Zasady doboru są tu w dużej mierze podobne do tych, jakich dokonujemy w przypadku klasycznych analiz ilościowych. Różnica polega na specyfice danych tekstowych.
Dane tekstowe składają się z ciągów znaków oddzielanych spacją lub innymi separatorami. Zawartością „komórki” danych tekstowych może być krótki tweet lub SMS, ale może być i książka. 100 rekordów może więc oznaczać 100 książek. Wybór danych do analizy będzie wpływał na kwestie techniczne typu: mechanizm dostępu, struktura, czy wolumen danych.
Jednak pytaniem zasadniczym jest to, czy ciągi znaków, które będziemy poddawać analizie, mają jakieś znaczenie? Tak naprawdę interesuje nas analiza treści, jaką niesie ze sobą dany tekst. Ciąg „xydk” nie ma żadnego znaczenia, natomiast „pies” to już coś innego. Ten drugi ciąg znaków reprezentuje zwierzę lub jak kto woli najlepszego przyjaciela człowieka.
Jak sprawdzić, czy dany ciąg znaków ma jakieś znaczenie?
Najprościej sprawdzić, czy występuje w słowniku. Tam możemy znaleźć ciągi znaków niosących za sobą określone znaczenia. Jakość zaklasyfikowania ciągów znaków jako mających znaczenie zależy w znacznej mierze od jakości słownika, jakim dysponujemy. Dobrze jest więc dysponować dobrym słownikiem języka polskiego. W przypadku PS CLEMENTINE PRO, którego składnikiem jest IBM SPSS Modeler, opieramy się na słowniku języka polskiego zawierającym ok. 311 tys. słów (form podstawowych). Uwzględniając odmianę, liczba wszystkich form reprezentowana w słowniku przekracza 6 mln. To bardzo obszerny, profesjonalny zasób językowy.

Rysunek 2. Kilka przykładów automatycznej poprawy tekstu
Niestety świetny słownik to za mało. Wyróżnienie ciągów znaków mających znaczenie zależy nie tylko od jakości słownika, ale i od jakości analizowanego tekstu. Jeśli przedmiotem analizy będzie zawartość książek, artykułów, czy różnych dokumentów o charakterze oficjalnym, można liczyć na to, że były one sprawdzane i poddawane korekcie. Nie gwarantuje to wprawdzie pełnej poprawności, ale można przynajmniej spodziewać się, że jakość będzie lepsza niż w przypadku danych pochodzących z czatów, forów itp.
Co, jeśli porównanie ze słownikiem zawiedzie?
W takiej sytuacji istnieje podejrzenie, że jest to błąd, może literówka, może błąd innego rodzaju. W edytorach tekstu wspomaga nas korekta podkreślająca niepoprawne ciągi znaków. Nie zawsze działa ona doskonale, jednak dzięki niej znacząco redukujemy liczbę popełnianych błędów. Jednak gdy korekta oznaczy wyraz jako błędny, to my decydujemy o poprawnej formie wyrazu, wybierając go z listy podpowiedzi lub wpisując ręcznie właściwy ciąg znaków. Trudno przyjąć taki tryb postępowania przy analizach typu Text Mining. Mając do czynienia z tysiącami rekordów, zawierających dane tekstowe, poprawa „słowo po słowie” nie wchodzi w grę. Słownik musi sam próbować różnych wariantów poprawy „nieznanego” ciągu znaków — powinien sprawdzać, czy to tzw. czeski błąd, czy może bliskość klawiszy na klawiaturze spowodowała literówkę itp. Próbując poprawić ciąg znaków, musi sprawdzić, czy występuje on w poprawionej formie w słowniku. Różnym próbom muszą zostać przypisane różne wagi, a następnie ma zostać wybrany wyraz o największej wadze. Wyraz taki zastępuje niepoprawny ciąg znaków.
Czy w wyniku tego procesu dostaniemy zawsze poprawny ciąg? Niestety, nie. Może się zdarzyć, że błędny ciąg znaków zostanie zastąpiony wyrazem występującym w słowniku, ale niepoprawnym w szerszym kontekście analizowanego tekstu. Wypracowanie idealnego mechanizmu rangowania i automatycznego poprawiania tekstu jest bardzo trudne. Może się też zdarzyć, że do danego ciągu znaków nie pasuje żadna sugestia.

Rysunek 3. Przykład błędów automatycznej korekty zmiennej tekstowej
Czy jest to duży problem?
Niekoniecznie. W przypadku ilościowej analizy dużego zbioru danych tekstowych, jeden czy kilka błędów nie musi mieć znaczącego wpływu na wyniki. Jeśli jednak mamy w tekście wyrazy, z którymi nie radzi sobie korekta automatyczna, a jest to dla nas istotne, możemy wymusić korektę regułową (zdefiniowaną przez użytkownika). Możemy ją wykonać przy użyciu narzędzi i funkcji wykorzystywanych do pracy z danymi tekstowymi.

Rysunek 4. Przykład regułowej (zdefiniowanej przez użytkownika)
poprawy tekstu poprzedzającej korektę automatyczną
Takie „ręczne” poprawki nie są też niczym nietypowym w przypadku klasycznych analiz statycznych. Proces analizy danych powinien być nadzorowany przez analityka na każdym etapie, w tym także na etapie przygotowania danych do analizy.
Ostatecznie i tak w danych tekstowych mogą się znaleźć ciągi niebędące wyrazami — ciągi znaków o specyficznym znaczeniu. W IBM SPSS Modeler są one nazywane encjami nielingwistycznymi. Do tego typu encji można zaliczyć np.: daty, kody pocztowe, numery PESEL i NIP, ceny. Ich wyodrębnienie z tekstu jest możliwe poprzez porównanie z określonymi „maskami” (formatami). Wydobywanie z tekstu tego typu ciągów odbywa się przy wykorzystaniu wyrażeń regularnych. Z ich pomocą można zbudować definicję, a następnie rozpoznawać kody pocztowe, czy daty.
Podsumowując, w pierwszym kroku dążymy do podniesienia jakości danych. Przy czym jakość, jaką chcemy uzyskać na wyjściu, musi być wystarczająca z punktu widzenia celu analiz. Dążąc do jakości idealnej, musimy pamiętać o ograniczających nas kryteriach takich jak: czas i budżet przeznaczony na analizę.
Analiza morfologiczna i ujednoznacznienie
W analizowanym tekście chcemy identyfikować znaczenia kryjące się za poszczególnymi ciągami znaków. Analiza znaczeń nie jest jednak łatwa przy wykorzystaniu komputerów. Powodów jest wiele, a jednym z istotniejszych jest to, że różne ciągi znaków mogą mieć takie samo znaczenie. Dzieje się tak np. w przypadku synonimów, ale do tego tematu jeszcze wrócimy. Istnieje jednak poważniejszy problem, związany z językiem polskim, a jest nim bardzo rozbudowana fleksja.

Rysunek 5. Odmiana czasownika dymić za SGJP
O wiele łatwiej pracuje się z tekstem w języku angielskim, ponieważ z perspektywy kryteriów morfologicznych jest to język zaliczany raczej do grupy języków izolujących. W takich językach większość morfemów to samodzielne wyrazy. Pomijając tutaj głębsze wchodzenie w tematykę podziału języków na podstawie kryteriów morfologicznych, można powiedzieć, że język polski jest znacznie bardziej skomplikowany. Zalicza się go do grupy języków fleksyjnych, gdzie na wyraz składa się morfem znaczeniowy i jeden lub więcej morfemów gramatycznych. [1]
Ta różnica pomiędzy językami — polskim i angielskim — jest bardzo ważna i skutkuje różnym podejściem do komputerowej analizy tekstu.
W efekcie, aplikacje do analizy tekstu budowane z myślą o języku angielskim, najczęściej nie będą sobie radzić z analizą polskiego tekstu. Z punktu widzenia języków programowania dwa ciągi uznane są za zgodne, jeśli są dokładnie takie same.
Z punktu widzenia języka naturalnego, końcówki fleksyjne nie muszą zmieniać znaczenia wyrazu, a w języku polskim jest ich dużo. Komplikuje to porównywanie ciągów tekstowych ze sobą. My wiemy, że jeśli mamy do czynienia z wyrazem „dymić” w różnych odmianach, to dalej chodzi o wyraz „dymić”. Problem polega na tym, że nasz tekst ma analizować komputer. Jak poradzić sobie z sytuacją, w której dwa ciągi znaków nie są dokładnie takie same, ale mają to samo znaczenie?
Zasadniczo są dwa główne sposoby radzenia sobie z fleksją. Pierwszy to stemming. Jest on mniej kosztowny obliczeniowo i dobrze sprawdza się wobec takich języków jak angielski. Polega na wyodrębnianiu rdzenia wyrazu poprzez sprawdzanie, czy występuje końcówka fleksyjna. Istnieją różne, mniej lub bardziej rozbudowane algorytmy stemmingu wykorzystywane w analizie danych tekstowych. Nie zmienia to jednak faktu, że fleksja języka polskiego jest na tyle złożona, iż stanowi ona poważne wyzwanie dla tego typu algorytmów.
W przypadku języka polskiego o wiele lepiej sprawdza się uprzednia lematyzacja tekstu, czyli sprowadzanie poszczególnych wyrazów do formy podstawowej. Np. sprowadzenie wszystkich czasowników do bezokolicznika. Nie jest to jednak proces prosty. Jest też bardziej kosztowny obliczeniowo. Kryje się za nim rozbudowana analiza obejmująca segmentację tekstu i analizę morfologiczną. Przeprowadzenie lematyzacji wymaga odpowiednich zasobów językowych.

Rysunek 6. Formy podstawowe dla poszczególnych części mowy

Rysunek 7. Przykład lematyzacji w wykorzystaniu modułu Applica AMS
Ekstrakcja pojęć
Sprawdzenie poprawności i lematyzacja poprzedzają kolejny etap, jakim jest wyodrębnianie pojęć. Pojęcie to:
- Wyraz (np. pokój, wybory), czyli „elementarna jednostka języka, znak pewnego przedmiotu lub pewnej treści” [2]
- Wyrażenie (np. pokój dzienny, wybory prezydenckie), czyli „połączenie wielowyrazowe o postaci grupy imiennej, np. biały kruk, lub wyrażenia przymiotnikowego, np. w gorącej wodzie kąpany [3]
- Synonim (np. auto i samochód), czyli „każdy z pary wyrazów mających takie samo znaczenie”[4]
Pojęcia i relacje między nimi są istotnym nośnikiem znaczeń w analizowanym tekście i będą wykorzystywane do budowy kategorii. Na wyodrębnianie pojęć w IBM SPSS Modeler wpływają:
- Kryteria regułowe, np. definicje opcji nielingwistycznych,
- Kryteria statystyczne, np. częstość występowania pojęcia,
- Zasoby lingwistyczne, np. słowniki, szyk wyrazów w zdaniu.
Kluczowe znaczenie przy wyodrębnianiu pojęć ma zastosowanie i odpowiednie sterowanie zasobami lingwistycznymi. Zmiana ustawień może prowadzić do zupełnie innych wyników. Przykładowo, jeśli weźmiemy dowolny tekst i uruchomimy mechanizm ekstrakcji pojęć, to bardzo prawdopodobne, że najczęściej występującymi pojęciami będą spójniki i np. czasownik „być”. W praktyce, w większości zastosowań pojęcia te są dla nas nieużyteczne, jeśli nie są wyodrębniane jako części wyrażeń.
To, co nas może szczególnie interesować to ekstrakcja rzeczowników. Oznacza to, że w zasobach lingwistycznych musi znajdować się informacja o częściach mowy przypisanych do poszczególnych wyrazów. Jeśli chcemy koncentrować się na wyodrębnianiu rzeczowników jako pojęć, musimy też wziąć pod uwagę wyrazy, które nie wystąpiły w zasobach językowych. Program będzie je wyodrębniał tak, abyśmy mieli szansę je zobaczyć, a następnie podjąć wobec nich odpowiednie działania (np. zostawić jako pojęcie i dopisać do słownika).
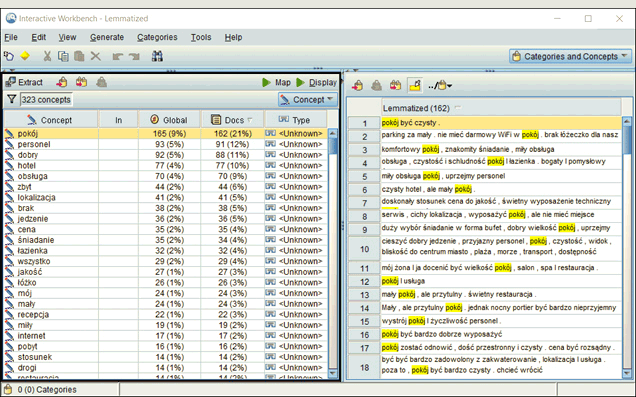
Rysunek 8. Przykład wyodrębniania rzeczowników
Drugi problem jest związany z wyrazami, które mogą być przypisane do więcej niż jednej części mowy. Przykładowo, „dobry” bylibyśmy skłonni traktować jako przymiotnik (np. „dobry hotel”), z drugiej strony „dobry” jest też rzeczownikiem rozumianym jako ocena w szkole. Od nas zależy, jak takie wyrazy będą traktowane przy wyodrębnianiu, a dokładniej od tego, jak wpłyniemy na konfigurację zasobów językowych.
Ten przykład zwraca uwagę na poważny problem, jakim jest wyodrębnianie tylko i wyłącznie wyrazów bez wzięcia pod uwagę kontekstu, w jakim dany wyraz występuje. Kontekst wpływa nie tylko na właściwe rozpoznanie części mowy, ale też na rozpoznanie znaczenia wyrazu.
Homonimia to „identyczność brzmienia i pisowni wyrazów mających różne znaczenia i zwykle też różne pochodzenie”.[5] Na przykład „zamek” może oznaczać budowlę, mechanizm zabezpieczania drzwi lub suwak w ubraniu. Aby mieć możliwość rozróżniania wyrazów o takiej samej pisowni, ale różnym znaczeniu musimy mieć możliwość wyodrębniania wyrażeń. Oznacza to, że w zasobach językowych musi istnieć możliwość wyodrębnienia części mowy współwystępujących w określonym szyku. Przykładowo, jeśli zdefiniujemy w opcjach możliwość tworzenia wyrażeń na podstawie szyku rzeczownik + przymiotnik, to będzie możliwość rozróżnienia pomiędzy „zamkiem drzwiowym”, a „zamkiem błyskawicznym”. Na tym „zabawa” z definicją zasobów językowych się nie kończy, bo przecież możemy mieć „zamek do drzwi”.
Program do analizy tekstu powinien nam zapewnić możliwość odpowiedniej konfiguracji w zależności od celu i zawartości analizowanego tekstu.

Rysunek 9. Przykład uwzględnienia szyku wyrazów w zdaniu w procesie wyodrębniania pojęć
Zdefiniowanie występowania członów określanego i określającego w różnej konfiguracji nie kończy wpływu zasobów lingwistycznych na wyodrębnianie pojęć. Dwa wyrazy mające różną pisownię mogą mieć to samo znaczenie. Mogą być synonimami. Na przykład „dym tytoniowy” i „dym papierosowy”. Także rozróżnianie płci i rozdzielne traktowanie „kelnera” i „kelnerki” może nie mieć znaczenia. To, czy pewne wyrazy lub wyrażenia będą traktowane jako synonimiczne, zależy od użytego słownika synonimów i jego ustawień. Docieramy tym samym do niezwykle istotnego zagadnienia tzn. do użycia słowników w procesie wyodrębniania pojęć. Na zasoby lingwistyczne składają się słowniki różnego typu, takie jak:
- Wykluczeń,
- Synonimów,
- Typów,
- Elementów opcjonalnych,
- Wyjątków,
- Skrótów,
- Normalizacyjny.
W dalszym opisie skupmy się na pierwszych trzech rodzajach słowników.
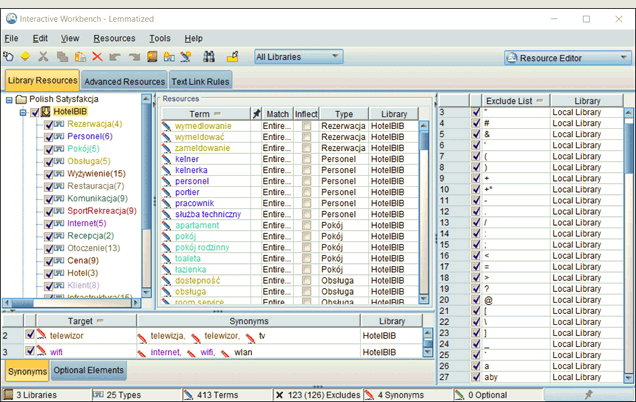
Rysunek 10. Okno zarządzania słownikami w IBM SPSS Modeler
Na słownik wykluczeń będą się składać zazwyczaj: przyimki, zaimki, partykuły, spójniki i różne znaki specjalne, przy czym zależnie od rodzaju analizy możemy chcieć wyłączać wybrane terminy lub ich grupy ze słownika wykluczeń.
Słownik synonimów służy do przechowywania informacji o wyrazach mających takie samo znaczenie. Ma on jednak dodatkowe zastosowania takie jak: przechowywanie wyrazów z nierozpoznanymi na wcześniejszych etapach formami fleksyjnymi, czy specyficznymi błędami pisowni. Zarządzając słownikiem synonimów, należy zwrócić uwagę, by zawierał on faktyczne synonimy, a nie wyrazy podobne, czyli „auto” i „samochód”, ale już nie „autobus”. Za grupowanie terminów, które zdaniem analityka są znaczeniowo podobne, odpowiadają słowniki typów.
Słownik typów to zbiór terminów zgrupowanych pod jedną wspólną etykietą lub nazwą. Typy grupują pojęcia pod względem semantycznym — zawierającym wyrazy mające z naszego punktu widzenia coś wspólnego. Słowniki typów można podzielić na takie, które są uniwersalne, a zakres pojęć w nich występujących jest znany z góry oraz te, które są trudne do określenia, a zawarte w nich pojęcia nie są łatwe do predefiniowania. Przykładowo, do pierwszej grupy możemy zaliczyć słownik: imion, miast, kolorów. W przypadku drugiej grupy może to być np. słownik nazwisk.
W praktyce często będzie też tak, że te same pojęcia mogą znaleźć się w różnych słownikach, a my będziemy wybierali właściwy słownik w zależności od celu analizy. Możemy mieć na przykład słownik pojazdy, do którego możemy zaliczyć takie pojęcia jak: „samochód”, „rower”, „motocykl”, „autobus”, „metro”. W zależności od kontekstu taki słownik może zostać rozbity na słownik komunikacja miejska lub komunikacja zbiorowa. W efekcie może to być podzbiór pojęć ze słownika pojazdy, a zakwalifikowanie „samochodu” do środków komunikacji zbiorowej może być dyskusyjne, ale niekoniecznie wykluczone.
Przykładowe słowniki:
- Warzywa : marchew, szpinak, brokuł, kalafior,
- Imiona : Adam, Beata, Bogdan, Celina, Filip,
- Miasta: Warszawa, Kraków, Gdańsk, Poznań,
- Pojazdy: samochód, rower, motocykl, autobus, metro,
- Pomieszczenia: pokój, kuchnia, łazienka, przedpokój, sypialnia,
Prowadząc nasze analizy, staramy się wykorzystać w nich już posiadane słowniki, często jednak będziemy też zmuszeni do budowy nowych słowników na potrzeby konkretnej analizy. W przypadku posiadanych słowników, co najwyżej uzupełniamy je o kolejne pojęcia znalezione w analizowanym tekście. Nowe, tworzymy na potrzeby konkretnej analizy poprzez nadanie nazw i dodawanie do nich wybranych pojęć z analizowanego tekstu.

Rysunek 11. Przykład wyodrębniania pojęć z ich przypisaniem do słownika typów
Używanie i konfigurowanie słowników typów jest zależne od analityka i ma charakter subiektywny. W efekcie, dwóch różnych analityków może mieć kompletnie różne podejście do tworzenia i używania słowników.

Rysunek 12. Przykład wyodrębniania typów
Posługiwanie się słownikami typów prowadzi w konsekwencji do wyodrębniania nie tylko pojęć, ale też i typów. W efekcie, w następnym etapie, czyli w budowie kategorii możemy się posługiwać nie tylko pojęciami przypisanymi do poszczególnych typów, ale też bezpośrednio typami.
Budowa kategorii
Przedostatnim etapem Text Miningu typów, to etapy wymagające znaczącej ingerencji ze strony analityka, ponieważ kategorie z natury mają charakter bardzo subiektywny. To analityk wie, w jakich kategoriach powinien spojrzeć na analizowany tekst i to on wie, do czego będą wykorzystywane wyniki (a przynajmniej powinien wiedzieć :)). Może jednak zdarzyć się, że będzie miał problem z formułowaniem hipotez, dlatego w IBM SPSS Modeler znajdzie szereg narzędzi do eksploracyjnej analizy tekstów: od listingów z zaznaczaniem fragmentów tekstu, przez raporty o charakterze tabelarycznym, do różnego typu wykresów. Ostatecznie jednak to analityk będzie tworzył lub przynajmniej współtworzył kategorie. To drugie przy założeniu, że do ich tworzenia będzie używał także algorytmów automatycznej kategoryzacji.

Rysunek 13. Przykład kategorii i wizualizacji powiązań między nimi
Podejmując decyzję o ostatecznej kategoryzacji, obok kryteriów merytorycznych musimy wziąć pod uwagę szereg kwestii technicznych np. czy tworzyć kategoryzację:
- płaską czy hierarchiczną, jeśli tą drugą to jak głęboki ma być podział hierarchiczny;
- rozłączną czy wielokrotnego wyboru, gdzie dany rekord tekstowy może być klasyfikowany do więcej niż jednej kategorii;
- klasyfikującą wszystkie rekordy tekstowe, czy tylko wybierającą te o określonej treści;
- uwzględniającą szeroki czy wąski zakres pojęć wyodrębnionych w procesie ekstrakcji;
- opartą na częstości występowania i definicji odpowiednich progów częstościowych;
- jednego zbioru danych, czy też kategoryzację, która automatycznie będzie klasyfikować inne teksty.
Wszystkie te wymienione powyżej, a także kilka innych czynników będą decydowały o sposobie podejścia do kategoryzacji tekstu.

Rysunek 14. Przykładowe deskryptory i reguły opisujące kategorie
Przy tworzeniu kategorii będziemy się posługiwali deskryptorami i używali reguł. Deskryptory to nic innego jak wyodrębnione pojęcia, typy lub wzory zbudowane z użyciem TLA (Text Link Analysis). Wątek TLA pozostawię jednak poza tym artykułem, aby go znacząco nie rozbudowywać. Dysponując wyodrębnionymi pojęciami typu „czysty pokój”, „ładny apartament” możemy zdecydować, że będą one deskryptorami kategorii „Pozytywna ocena pokoju”. Grupując ze sobą odpowiednie deskryptory, możemy tworzyć interesujące nas kategorie. W efekcie dodania deskryptorów do kategorii, rekordy je zawierające będą klasyfikowane do danej kategorii.

Rysunek 15. Przykład tworzenia reguł opisujących kategorie
Drugim sposobem tworzenia kategorii jest budowanie ich z użyciem reguł. Przykładowo, możemy stworzyć regułę &
Produktem końcowym pracy jest stworzenie kategorii i przypisanie do nich analizowanego tekstu. Możemy też posłużyć się uprzednio stworzonym kluczem kodowym, by zaklasyfikować tekst do kategorii stworzonych wcześniej i zaimportowanych do programu.
Ten etap pracy może można uznać za końcowy, jeśli naszym celem było napisanie raportu z wynikami analizy tekstu. Może być jednak tak, że przygotowane i dostosowane zasoby lingwistyczne chcemy użyć do kategoryzacji nowego tekstu. Na przykład, odpowiedzi na pytania z kolejnych fal badań ankietowych, czy napływających nowych komentarzy z formularza internetowego do oceny satysfakcji. Możemy też chcieć prowadzić dalej analizy ilościowe, a przynależność do kategorii wyprowadzić jako dodatkowe zmienne, które zamierzamy użyć w analizie. Konieczne jest wtedy przejście do ostatniego kroku, czyli kategoryzacji.
Kategoryzacja danych
Ostatni krok to przekształcenie wyników poprzedniego kroku w model klasyfikacyjny, który kryje w sobie kategorie i ich deskryptory wraz z regułami oraz inne niezbędne zasoby do kategoryzacji nowych danych. Gotowy model można też podpiąć pod dane użyte w naszych analizach na poprzednich etapach.

Rysunek 16. Przykładowy model klasyfikujący dane
Efektem podpięcia modelu do danych będzie przypisanie każdemu rekordowi wartości zmiennej lub zmiennych opisujących przynależność do kategorii. Etap ten jest najprostszy w całej analizie danych tekstowych. Jeśli mamy gotowe kategorie, wystarczy tylko wybrać opcję utworzenia modelu klasyfikacyjnego. Następnie podpinamy model do danych tekstowych, które chcemy klasyfikować. Na tym etapie możemy podjąć jeszcze dwie decyzje. Pierwsza dotyczy wyboru zakresu kategorii, które mają być użyte do kategoryzacji. Druga jest związana ze sposobem przypisywania informacji o przynależności danego tekstu do kategorii.

Rysunek 17. Okno opcji kategoryzacji tekstu
Pierwszy sposób to kodowanie typu prawda-fałsz. W jego wyniku zostaną utworzone nowe zmienne w liczbie równej liczbie kategorii, a przynależność do kategorii będzie reprezentowana przez wartość prawda (np. „T”) w zmiennej reprezentującej tę kategorię.
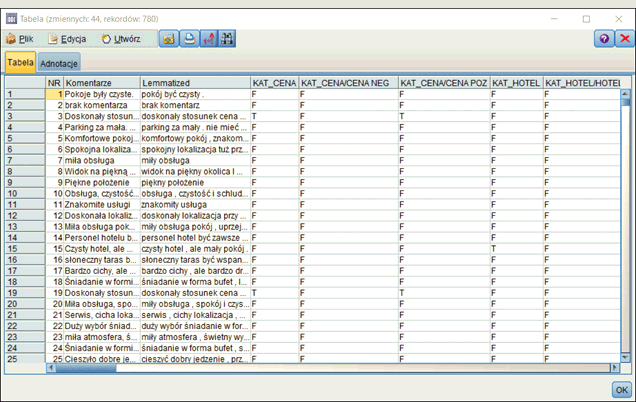
Rysunek 18. Przykład kategoryzacji tekstu jako zmiennych typu prawda-fałsz
Drugi sposób to kodowanie transakcyjne, gdzie każdy rekord zostanie powtórzony tyle razy, do ilu kategorii należy. W zbiorze danych będzie tylko jedna zmienna reprezentująca kategorie, której wartościami będą nazwy kategorii, do których dany rekord należy.

Rysunek 18. Przykład kategoryzacji transakcyjnej
Produktem końcowym etapu kategoryzacji są więc zmienne, które mogą być wykorzystane w dalszych analizach ilościowych, np. na potrzeby przeciwdziałania odchodzeniu klientów. Mogą to też być informacje do wyzwalania kampanii zdarzeniowych, czy to o charakterze utrzymaniowym, czy też sprzedażowym. Obszary zastosowań analiz danych tekstowych to już jednak temat zbyt obszerny na ten artykuł. W pojedynczym artykule nie sposób też opisać wszystkich zagadnień związanych z analizą tekstu ani wszystkich możliwości programu w tym obszarze.
… I PARĘ SŁÓW NA KONIEC
Na koniec dla zainteresowanych Text Miningiem parę przydatnych linków związanych z językiem polskim i narzędziami użytecznymi w komputerowych zmaganiach z nim:
- https://www.languagetool.org/pl/
- http://sgjp.pl/leksemy/#13589/a
- http://sgjp.pl/morfeusz/morfeusz.html.po
- http://zil.ipipan.waw.pl/PoliMorf
- http://clip.ipipan.waw.pl/LRT
[1] Źródło: Kryterium morfologiczne
[2] Słownik języka polskiego PWN: wyraz
[3] jw.: wyrażenie
[4] jw.: synonim
[5] jw.: homonimia