W tym wpisie dokonuję przeglądu kilku klasycznych modeli rzetelności. Na początku przyjrzymy się modelowi alfa Cronbacha, następnie przejdziemy do omówienia modelu rzetelności połówkowej i modelu Guttmana.

W tabeli 1 znajduje się wynik badania rzetelności skali stosunku do oszczędzania pieniędzy, złożonej z pięciu pozycji (szersze omówienie skali i poszczególnych pozycji znajduje się we wcześniejszych wpisach: Jak przygotować się do analizy rzetelności skali? oraz Podejmowanie decyzji o usunięciu pozycji ze skali. Alfa Cronbacha w tym przypadku wynosi 0,7. Z teoretycznego punktu widzenia, alfę Cronbacha można interpretować jako korelację pomiędzy naszą skalą a wszystkimi innymi (hipotetycznymi) skalami stosunku do oszczędzania, zawierającymi tę samą liczbę pozycji. Zdaję sobie sprawę, że w pierwszej chwili może to brzmieć dość abstrakcyjnie. Aby to zrozumieć, musimy wyobrazić sobie, że te pięć stwierdzeń, którymi dysponujemy, to tak naprawdę próba z populacji wszystkich możliwych stwierdzeń, które potencjalnie nadawałyby się do zmierzenia interesującego nas zjawiska. Ze względów praktycznych, nie możemy zadać respondentowi tak dużej liczby pytań, dlatego ze wszystkich potencjalnych stwierdzeń „losujemy” pewną próbkę. Gdybyśmy porównali wyniki pomiędzy naszą skalą a pozostałymi 5-elementowymi próbkami, korelacja między nimi wyniesie właśnie tyle, ile wynosi alfa Cronbacha.
Chcesz dowiedzieć się więcej o analizie rzetelności?
Zapraszamy na szkolenie AN2. Metodyka prowadzenia badań, raporty tabelaryczne i wykresy .
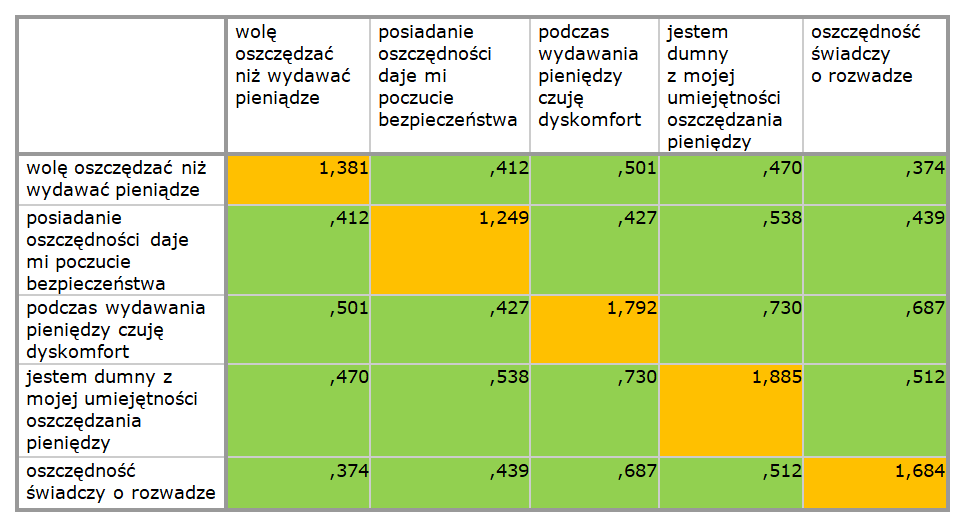
Aby dobrze zrozumieć, skąd się bierze wartość alfy Cronbacha i jak się ją interpretuje (tym razem już w praktyce), spróbujmy sami wyliczyć ten współczynnik. Nie będzie to trudne. Jedyne, czego będziemy potrzebować, to dane zawarte w MACIERZY KOWARIANCJI.
Alfa Cronbacha może być wyliczona przy zastosowaniu następującego wzoru:
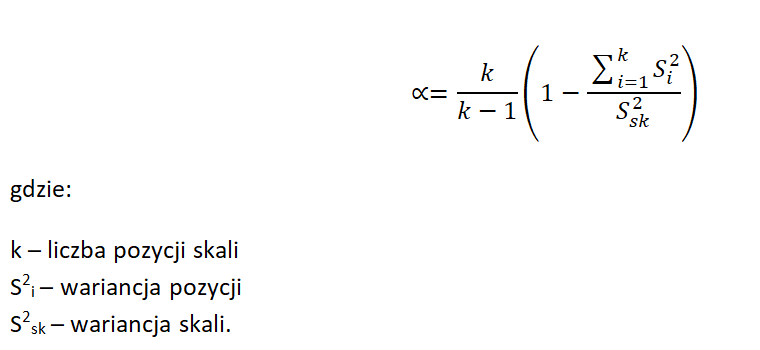 ;
;
Warto wiedzieć też, że wariancja skali, to suma indywidualnych wariancji pozycji skali powiększona o sumę wszystkich kowariancji pomiędzy pozycjami. W MACIERZY KOWARIANCJI indywidualne wariancje pozycji znajdują się na przekątnej (wartości te zaznaczone zostały kolorem pomarańczowym), a wszystkie pozostałe wartości to kowariancje pomiędzy pozycjami (zaznaczone kolorem zielonym). Uzbrojeni w tę wiedzę, możemy już obliczyć alfę Cronbacha:

Alfa Cronbacha przyjmuje wartości od 0 do 1, choć może się czasem zdarzyć, że alfa będzie ujemna. Dzieje się tak w przypadku pojawienia się ujemnych korelacji między pozycjami. W takim przypadku warto sprawdzić, czy wartości odpowiedzi zostały poprawnie zakodowane. Wartości alfy Cronbacha zbliżające się do 1 świadczą o dużej rzetelności skali. Skalę uznaje się za rzetelną, jeżeli wartość alfy Cronbacha wynosi przynajmniej 0,7. Regułę tę należy jednak traktować z przymrużeniem oka. Wartość alfy Cronbacha zależy bowiem również od ilości pozycji tworzących skalę. Wprowadzanie kolejnych pozycji, nawet jeśli są słabo skorelowane, poprawia zwykle wartość alfy Cronbacha. Dlatego w niektórych sytuacjach wartość 0,7 uznamy za niesatysfakcjonującą, w innych zaś – będziemy z takiego wyniku bardzo zadowoleni. W naszym przykładzie, wartość alfy Cronbacha jest akceptowalna.
Warto poświęcić jeszcze kilka chwil na przyjrzenie się wzorowi na alfę Cronbacha. Zauważmy, że alfa Cronbacha będzie wysoka, jeżeli wariancja całej skali jest dużo większa niż suma wariancji poszczególnych pozycji. Wysoka wariancja pozycji skali jest niewskazana, gdyż może świadczyć o dużych błędach pomiaru. Gdy zadajemy respondentowi pytanie w ankiecie, zakładamy, że na jego odpowiedź będą składały się: prawdziwy stan zjawiska oraz błąd losowy. Jeśli zadajemy pięć pytań zamiast jednego, zakładamy, że błędy się zniosą. W jednym pytaniu respondent zaznaczy trochę za wysoką wartość, w drugim pytaniu – trochę za niską, ale ponieważ błędy są losowe, to ostateczna wartość całej skali będzie odzwierciedlała prawdziwy stan badanego zjawiska[1]. A wariancja całej skali nie będzie już świadczyła o błędzie, lecz o zróżnicowaniu tego zjawiska. Jeśli wariancja całej skali jest dużo wyższa niż suma wariancji poszczególnych pozycji, świadczy to o wysokich kowariancjach pomiędzy pozycjami, co z kolei wskazuje na spójność skali.
Z Tabeli 1, oprócz wartości alfy Cronbacha, możemy odczytać również wartość tzw. standaryzowanej alfy Cronbacha. Obliczana jest ona ze wzoru:
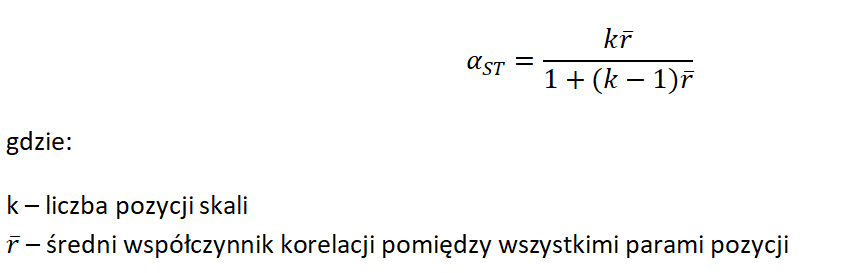
Jeśli liczba pozycji nie zmienia się, to wartość standaryzowanej alfy Cronbacha jest tym większa, im większa jest średnia korelacja między pozycjami. Warto też pamiętać, że przy stałej średniej korelacji pomiędzy parami pozycji, na wartość standaryzowanej alfy Cronbacha wpływa liczba pozycji, z których składa się skala.
Przejdźmy do modelu rzetelności połówkowej. Wyobraźmy sobie, że zamiast prezentować respondentowi wszystkie stwierdzenia skali na raz, przygotowujemy dla niego dwa osobne kwestionariusze. Na jednym drukujemy połowę pytań, na drugim – pozostałe. Respondent wypełnia dwa osobne testy. Po podliczeniu wyników okazuje się, że pierwszy test wskazuje na silne natężenie badanej postawy u respondenta. Jednak wynik drugiego testu tego nie potwierdza. W takiej sytuacji powiedzielibyśmy, że te dwa testy nie są ze sobą spójne i nie mierzą badanego zjawiska w sposób rzetelny.
Dzielenie skali na pół i sprawdzanie wzajemnej korelacji i spójności pomiędzy połówkami, to idea, która przyświeca modelom rzetelności połówkowej. W praktyce oczywiście nie musimy drukować dwóch osobnych kwestionariuszy dla naszych respondentów. Wystarczy, że na etapie analizy danych, program komputerowy podzieli zestaw zmiennych tworzących skalę, na dwie części. Oczywiście dążymy do tego, aby części były równe, ale w przypadku nieparzystej liczby pozycji nie jest to możliwe. Do pierwszej części będziemy musieli zaliczyć o jedną pozycję więcej niż do części drugiej. Stąd wynikają pewne problemy z nazewnictwem powstałych części. Konwencja każe pisać o „połówkach”, niezależnie czy mamy na myśli dwie równe czy też nierówne części. I chociaż nie istnieje coś takiego jak większa lub mniejsza połowa, pozwolą Państwo, że mimo wszystko będziemy posługiwać się tymi określeniami – przy pełnej świadomości występowania logicznej sprzeczności.
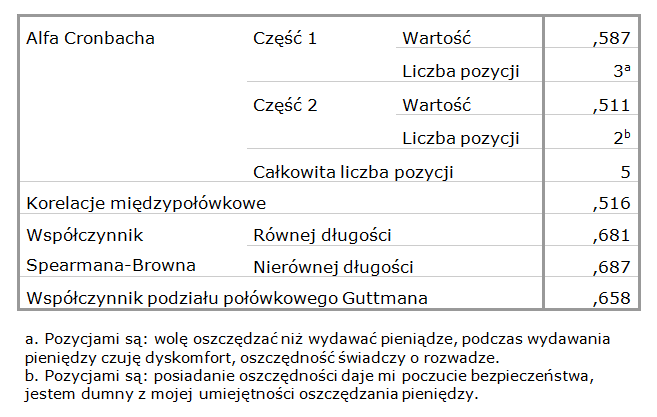
Popatrzmy na tabelę 3, która zawiera statystyki rzetelności w modelu połówkowym.

Jak Państwo zapewne już zauważyli, dla każdej połówki wyliczona została znana nam już alfa Cronbacha. Ponadto pojawiają się inne miary rzetelności, których omówieniem zajmiemy się za chwilę. Zerknijmy jeszcze na stopkę tabeli. Znajduje się tam informacja o tym, w jaki sposób program przypisał poszczególne pozycje skali do połówek. Jak widać, w skład pierwszej połówki weszły trzy pozycje, w skład drugiej natomiast – tylko dwie. Kolejność wprowadzania pozycji do połówek jest dokładnie taka, jak kolejność wprowadzania zmiennych do analizy. Wiąże się z tym pewien problem. Gdy zmienimy kolejność zmiennych w taki sposób, że zmieni się skład poszczególnych połówek, wyniki będą inne! Powstaje więc bardzo ważne pytanie: jaka powinna być kolejność wprowadzania zmiennych do okna dialogowego?
Najprościej byłoby, gdyby badani rzeczywiście wypełniali dwa osobne testy. Wtedy naszym celem jest sprawdzenie, czy te dwa narzędzia rzetelnie mierzą dane zjawisko. W takim przypadku będziemy chcieli, żeby połówki ściśle odzwierciedlały faktyczny skład zastosowanych testów. Jednak w praktyce, najczęściej będziecie Państwo spotykali się z inną sytuacją. Badani wypełniają zwykle jeden kwestionariusz, a analityk dopiero post factum, niejako w sposób sztuczny, dzieli skalę na dwie części. Wprowadzenie pozycji skali dokładnie w takiej kolejności, w jakiej były prezentowane respondentom, wiąże się z pewnymi niebezpieczeństwami (tym większymi, im więcej było pozycji skali). Respondenci podczas wypełniania długiej ankiety mogą odczuwać znużenie, skutkujące coraz mniejszą starannością odpowiadania na pytania. Dlatego rekomenduje się, aby przypisywanie pozycji skali do połówek odbywało się w sposób losowy. Innym sposobem jest wprowadzenie do jednej połówki pozycji parzystych, a do drugiej – nieparzystych[2]. Proponuję w naszym przypadku zastosować właśnie ten sposób. Wykonajmy więc jeszcze raz analizę rzetelności, ale tym razem do pierwszej połówki wprowadzimy pierwszą, trzecią i piątą pozycję, a do drugiej połówki – pozycję drugą i czwartą. Teraz najwyższy czas, żeby omówić wyniki tabeli ze statystykami rzetelności modelu połówkowego oraz dowiedzieć się w jaki sposób wyliczane są poszczególne wartości.
Korelację pomiędzy połówkami można wyliczyć ze wzoru:

Wszystkie wartości potrzebne do obliczenia korelacji pomiędzy połówkami znajdziemy w tabeli STATYSTYKI POZYCJI.

W obliczeniach najlepiej skorzystać z dokładnych wartości skopiowanych z tabeli w oknie raportów (nie ograniczając się tylko do trzech miejsc po przecinku). 
Korelację między połówkami można interpretować jako korelację R Pearsona pomiędzy wartościami dwóch skal, wyliczonych dla indywidualnych obserwacji z wykorzystaniem pozycji z pierwszej i drugiej połówki.
W tabeli wynikowej dostajemy dodatkowo wyniki dla trzech miar: współczynnik Spearmana-Browna równej długości i nierównej długości oraz współczynnik podziału połówkowego Guttmana. Przyjrzyjmy się im.
Bardzo podobnie jak korelacja międzypołówkowa obliczany jest współczynnik podziału połówkowego Guttmana. W liczniku różnica pomiędzy wariancją skali a wariancjami połówek pomnożona jest przez 2, a w mianowniku, zamiast iloczynu odchyleń standardowych połówek, występuje wariancja całej skali:

Z tą miarą jeszcze się spotkamy, gdy będziemy omawiać model rzetelności Guttmana.
Pozostały nam jeszcze dwie miary Spearmana-Browna. Współczynnik Spearmana-Browna dla połówek o równej długości mówi o tym jaka byłaby rzetelność skali, gdyby składała się ona z dwóch części o równej liczbie pozycji i o korelacji między tymi połówkami równej 0,516. Wzór na ten współczynnik jest bardzo prosty. Żeby go obliczyć wystarczy znać wartość korelacji między połówkami (R).

Druga miara mówi o rzetelności skali, której „połówki” są nierównej długości. Czyli odnosi się do naszego przykładu. Wzór na wyliczenie tego współczynnika jest trochę bardziej skomplikowany, między innymi dlatego, że konieczne jest wzięcie pod uwagę liczby pozycji skali oraz poszczególnych części tej skali. Tych z Państwa, którzy są szczególnie zainteresowani tematem, zachęcam do zapoznania się z zamieszczonym poniżej wzorem, pozostałych zaś uspokajam, że więcej wzorów w tym wpisie już nie będzie.

Wartość współczynnika rzetelności połówkowej Spearmana-Browna wynosi w naszym przykładzie 0,687 („połówki” są nierównej długości). Nie jest to zły wynik, ale trudno też uznać go za szczególnie dobry. Sugeruje, że nad skalą warto byłoby jeszcze popracować. Być może powinniśmy zmienić brzmienie niektórych stwierdzeń lub dodać nowe. To pokazuje nam, że zanim zaczniemy realizować badanie, powinniśmy przeprowadzić szereg badań pilotażowych. Takie wstępne badania na niewielkich próbach pozwolą nam przetestować różne wersje kwestionariusza. Dzięki temu uzyskamy taki zestaw stwierdzeń, który umożliwi dokonanie rzetelnego pomiaru interesującego nas zjawiska. Jest to ważne zwłaszcza wtedy, gdy sami konstruujemy skalę i gdy nie była ona jeszcze nigdy testowana pod kątem rzetelności[3]. Na potrzeby naszego ćwiczenia, uzyskaną w modelu połówkowym rzetelność uznajemy za wystarczającą.
Sprawdzimy teraz jakie wyniki uzyskamy, gdy zastosujemy model Guttmana. Jego autor, Louis Guttman był profesorem socjologii i psychologii. Zajmował się w szczególności problematyką teorii pomiaru. W 1971 roku, na łamach amerykańskiego czasopisma naukowego „Science”, zaliczony został do grona 62 naukowców, najbardziej zasłużonych dla rozwoju nauk społecznych w XX wieku. Zajmując się analizą rzetelności skal, zaproponował sześć miar rzetelności, które nazwał lambdami. Wszystkie te miary są próbą oszacowania dolnej granicy rzetelności. Oznacza to, że prawdziwa rzetelność może być taka sama lub wyższa, niż dana miara rzetelności, ale nie może być od niej niższa.
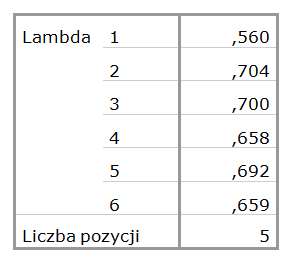
Na początek warto wiedzieć, że dwie spośród tych miar już znamy. Lambda 3 to nic innego jak znana nam już alfa Cronbacha (porównaj wynik – tabela 1), a lambda 4 to współczynnik podziału połówkowego Guttmana, z którym spotkaliśmy się, przy omawianiu modelu rzetelności połówkowej (porównaj – tabela 4). Oczywiście, musimy wciąż pamiętać, ze wartość lambda 4 jest zależna od kolejności wprowadzania zmiennych do analizy. Lambda 1 jest miarą pomocniczą. Stanowi bazę do obliczania pozostałych lambd. Sama w sobie nie jest stosowana do szacowania rzetelności skali, gdyż znacząco zaniża rzeczywistą wartość rzetelności. Prawdziwą wartością dodaną w tym modelu jest lambda 2, która w porównaniu do alfy Cronbacha, lepiej estymuje dolną granicę rzetelności. Lambdy 5 i 6 stosowane są w szczególnych przypadkach. Lambda 5 przyjmuje wyższą wartość (i jednocześnie uznaje się, że lepiej szacuje rzetelność) wtedy, gdy jedno ze stwierdzeń ma szczególnie wysokie wartości kowariancji ze wszystkimi innymi stwierdzeniami, podczas gdy pomiędzy pozostałymi stwierdzeniami wartości kowariancji są niskie. Lambda 6 natomiast rekomendowana jest wtedy, gdy korelacje między poszczególnymi pozycjami są niskie w porównaniu do kwadratów korelacji wielokrotnej (wartości współczynnika R-kwadrat).
Ponieważ wszystkie powyższe miary są oszacowaniem dolnej granicy rzetelności, należy wybrać największą z nich. W naszym przypadku możemy więc przyjąć, że prawdziwa wartość rzetelności nie jest niższa niż 0,704. Model Guttmana potwierdza więc, że skalę możemy uznać za rzetelną. Omówiliśmy wszystkie klasyczne modele rzetelności. Pozostaje nam zatem utworzyć skalę i wykorzystać ją do dalszych analiz.