To wcale nie musi oznaczać, że model został źle zbudowany. Bardzo często problem leży gdzie indziej – w danych, w definicji celu albo w tym, że predykcja nie została dobrze dopasowana do realnego procesu decyzyjnego.
Jakość modeli predykcyjnych warto więc rozumieć szerzej niż tylko jako dobra metryka statystyczna. Jak zatem zwiększyć skuteczność modeli predykcyjnych?
Skuteczność to coś więcej niż dobra metryka
Model predykcyjny można uznać za skuteczny dopiero wtedy, gdy spełnia trzy warunki.
- Trafność: Poprawnie przewiduje interesujące nas zjawisko.
- Użyteczność: Jego wynik da się sensownie wykorzystać w decyzjach biznesowych.
- Stabilność: Działa stabilnie w czasie i można go utrzymać w produkcji.
W praktyce często okazuje się, że model z nieco gorszą metryką daje lepszy efekt biznesowy, bo jest lepiej osadzony w procesie: uruchamia się regularnie, korzysta z aktualnych danych i trafia do osób, które faktycznie podejmują decyzje.
Narzędzie analityczne PS CLEMENTINE PRO zostało zaprojektowane właśnie z myślą o takim podejściu procesowym – model nie jest tu celem samym w sobie, ale elementem większego strumienia analitycznego i całego procesu.
Dobrze widać to na przykładzie modelu przewidującego wystąpienie rzadkiego przypadku np. powikłania po zabiegu, które pojawia się średnio u 1 pacjenta na 10 000. Jeśli ocenialibyśmy model wyłącznie na podstawie procentowej wartości trafności, moglibyśmy otrzymać rozwiązanie, które w każdej sytuacji przewiduje „brak powikłania”. Taki model osiągałby trafność na poziomie 99,99%, a mimo to nie spełniałby swojej funkcji. W praktyce to właśnie te nieliczne, ale krytyczne przypadki są najważniejsze i to ich wykrywalność powinna być kluczowym kryterium oceny skuteczności modelu. W tym przypadku jednym z rozwiązań jest dokonanie balansowania zbioru danych, przed etapem uczenia modelu.
Jedna definicja celu, jeden sens biznesowy
„Churn”, „ryzyko”, „awaria” – te pojęcia brzmią znajomo, ale w praktyce mogą w różnych kontekstach oznaczać zupełnie różne rzeczy. Czy churn to brak aktywności przez 30 dni, 90 dni, czy formalne wypowiedzenie umowy? Czy interesuje nas każde opóźnienie w płatności, czy tylko te powyżej określonej kwoty?
Jeśli definicja zmiennej celu nie jest jasno ustalona na początku projektu, model może być trudny do interpretacji, a jego wyniki – niespójne z oczekiwaniami biznesu. Skuteczność rośnie wtedy, gdy cel jest nie tylko dobrze opisany, ale też powiązany z działaniem, które organizacja rzeczywiście jest w stanie podjąć.
Zadbaj o moment predykcji
Jednym z najczęstszych błędów w projektach predykcyjnych jest nieuwzględnienie momentu, w którym podejmowana jest decyzja.
Model może „wiedzieć za dużo”, jeśli w wykorzystywanych predyktorach pojawią się informacje dostępne w praktyce dopiero po fakcie. Wtedy jego jakość w testach będzie bardzo wysoka, ale po wdrożeniu szybko okaże się, że w rzeczywistości nie da się go użyć.
Dobra praktyka jest tu prosta: warto jasno określić, w którym momencie liczony jest scoring i jakie dane są wtedy dostępne. Dopiero na tej podstawie powinno się budować zbiór predyktorów, z których korzystać będzie algorytm. W środowisku PS CLEMENTINE PRO, gdzie cały proces jest widoczny jako strumień kroków, znacznie łatwiej wychwycić takie nieścisłości i utrzymać spójną logikę analizy.
Dane: im mniej chaosu, tym lepsza predykcja
W wielu przypadkach największy wzrost jakości modelu nie wynika ze zmiany algorytmu, lecz z lepszego przygotowania danych.
Braki danych, niespójne formaty, błędne wartości czy obserwacje nietypowe potrafią skutecznie zaburzyć proces uczenia. Co ważne, nie każda wartość odstająca jest błędem – czasem to właśnie anomalia jest sygnałem, który chcemy wykryć. Kluczowe jest więc rozróżnienie, co należy skorygować, a co zachować.
W PS CLEMENTINE PRO przygotowanie danych jest integralną częścią strumienia analitycznego. Użytkownik ma dostępnych szereg węzłów z różnymi procedurami – takimi jak rekodowanie, kategoryzacja, czy anonimizacja, a nawet Auto przygotowanie, które pozwala na otrzymanie automatycznych rekomendacji przekształceń i zastosowanie wszystkich lub wybranych zmian w danych. Dzięki takiemu podejściu łatwiej poprawić dane, ponownie przeliczyć model i od razu zobaczyć, jaki ma to wpływ na wyniki.


Dobór odpowiedniego algorytmu
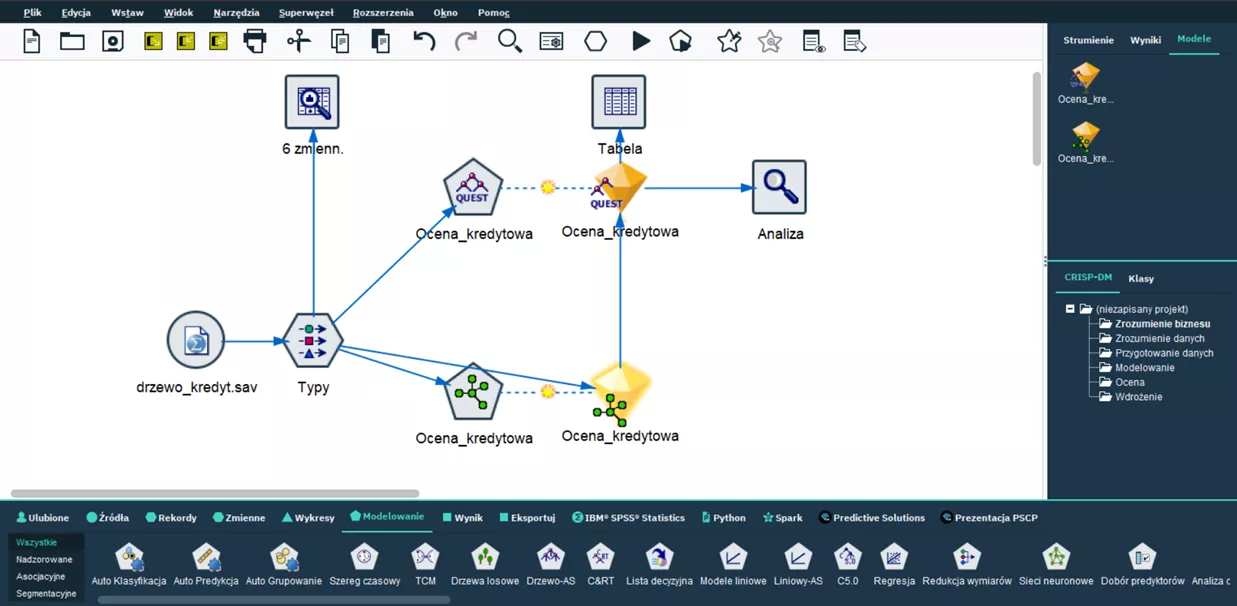
Częstą pułapką jest przywiązanie do jednego, sprawdzonego algorytmu. Tymczasem skuteczność modeli w praktyce rośnie wtedy, gdy różne podejścia są porównywane w uporządkowany sposób, na tych samych danych i według tych samych kryteriów.
Mechanizmy automatycznego porównywania modeli, dostępne w PS CLEMENTINE PRO, pozwalają szybko sprawdzić, które podejście najlepiej sprawdza się w danym problemie. Zamiast zgadywać, można oprzeć się na wynikach i skupić na dalszym dopasowaniu modelu do procesu biznesowego.
W tym miejscu warto jednak wrócić do postawionego celu biznesowego. Jeśli nasz model ma wyłapywać przypadki wyłudzeń, podczas podejmowania decyzji będziemy się kierować raczej jak najwyższym poziomem trafności modelu, nawet jeśli na wynik scoringu trzeba będzie dłużej czekać. Wynika to z sięgania po bardziej zaawansowane algorytmy predykcyjne, takie jak las losowy czy sieć neuronowa.
Jeśli natomiast model miałby służyć do wstępnej, niezobowiązującej decyzji dot. kredytu czy leasingu, skłanialibyśmy się raczej ku wykorzystaniu prostszych algorytmów, jak drzewa decyzyjne, które pomimo nieco gorszej trafności, przekazywałyby odpowiedzi na zapytania niemal w czasie rzeczywistym.

Wychodząc z jednego zbioru danych, model drzewa decyzyjnego QUEST przewidywał poprawnie 81,13% przypadków, a model lasu losowego tylko w jednym przypadku dokonał innej predykcji niż znajdowała się w oryginalnej zmiennej przewidywanej Ocena_kredytowa, tym samym mając trafność na poziomie aż 99,96%.
Próg decyzyjny ma znaczenie
Model predykcyjny może przewidywać zmienne ilościowe, na przykład szacowany czas eksploatacji maszyny do momentu konieczności serwisu, może przewidywać przynależność do określonej kategorii, ale też prognozować zmienną flagową, taką jak kupi/nie kupi czy odejdzie/nie odejdzie. Niezależnie od rodzaju zadania, w PS CLEMENTINE PRO dla każdego rekordu (czyli każdej obserwacji) otrzymujemy również informację o prawdopodobieństwie poprawności danej predykcji, co pozwala świadomie decydować, jak wykorzystać wynik modelu w praktyce.
Inny próg będzie sensowny, gdy mamy ograniczony budżet i możemy objąć działaniem tylko część przypadków, a inny wtedy, gdy ważniejsze jest niewypuszczenie z pola widzenia żadnego ryzykownego zdarzenia. Dlatego warto patrzeć na model przez pryzmat tego, jakie decyzje będzie wspierał w praktyce, a nie tylko przez pryzmat jednej liczby podsumowującej jego jakość.

$R – predykcja dokonywana przez model (w wartościach oryginalnej zmiennej przewidywanej),
$RC – prawdopodobieństwo pewności danej predykcji (w zakresie od 0 do 1)
Model to dopiero początek: liczy się proces
Największa różnica między modelem, który „jest”, a modelem, który „działa”, pojawia się po wdrożeniu.
Automatyczne uruchamianie zadań, harmonogramy, repozytorium do pracy zespołowej i czytelna struktura procesu sprawiają, że model staje się częścią codziennego funkcjonowania organizacji, a nie jednorazowym eksperymentem analitycznym. PS CLEMENTINE PRO wspiera takie podejście, umożliwiając zarówno cykliczne uruchamianie analiz, jak i reagowanie na konkretne zdarzenia w systemach biznesowych.
Warto też pamiętać o utrzymaniu jakości w czasie. Zmiany w danych i zachowaniach klientów są naturalne, dlatego skuteczny model to taki, który jest regularnie monitorowany i w razie potrzeby aktualizowany.

PS CLEMENTINE Manager to aplikacja służąca do uporządkowanego przechowywania zasobów analitycznych, organizowania i zarządzania pracą grupową oraz do automatyzacji pracy. To miejsce, gdzie współpracują ze sobą analitycy oraz użytkownicy biznesowi korzystający z wyników pracy analityków.
Podsumowanie
Zwiększenie skuteczności modelu predykcyjnego rzadko sprowadza się do „podkręcenia” algorytmu. Znacznie częściej chodzi o uporządkowanie celu, dopasowanie momentu predykcji do realnej decyzji, świadomą pracę z danymi oraz właściwą interpretację wyniku.
Model zaczyna mieć realną wartość dopiero wtedy, gdy jest częścią większego procesu: gdy wiadomo, kto i na jakiej podstawie podejmuje decyzję, gdy próg działania jest dopasowany do możliwości organizacji, a cały mechanizm działa stabilnie w czasie.
PS CLEMENTINE PRO wspiera takie podejście, łącząc budowę modeli, przygotowanie danych i automatyzację w jednym środowisku. Dzięki temu predykcja przestaje być jednorazową analizą, a staje się narzędziem realnie wspierającym zarządzanie.