Jednym z narzędzi, które im w tym pomaga, jest algorytm SVM (ang. Support Vector Machine). Dzięki swojej wszechstronności i precyzji znalazł zastosowanie w różnych branżach, od finansów po medycynę, i wciąż zyskuje na popularności. Narzędzia takie jak PS CLEMENTINE PRO ułatwiają wykorzystanie algorytmu SVM. Intuicyjny interfejs, zaawansowane funkcje analizy oraz możliwość wizualizacji wyników pozwalają użytkownikom szybko i efektywnie wdrożyć modele SVM w praktyce. Dzięki temu analitycy mogą skupić się na wyciąganiu wniosków i podejmowaniu decyzji, zamiast tracić czas na skomplikowane procesy techniczne.
Jak działa algorytm SVM?
Support Vector Machine to algorytm uczenia maszynowego, który koncentruje się na klasyfikacji danych oraz regresji. Jego celem jest zbudowanie takiego modelu, który najlepiej oddziela klasy w zbiorze danych.
SVM to zatem algorytm, który pomaga rozdzielić dane na grupy lub przewidzieć, do której grupy należą nowe dane. Działanie tego algorytmu można opisać jako proces znajdowania najlepszego sposobu podziału zbioru danych, tak, aby nowy punkt mógł być przypisany do odpowiedniej grupy na podstawie wcześniej nauczonego modelu SVM. Jego zadaniem jest znalezienie optymalnej granicy (tzw. hiperpłaszczyzny), która najlepiej oddziela te grupy, jednocześnie pozostawiając odpowiedni margines bezpieczeństwa.
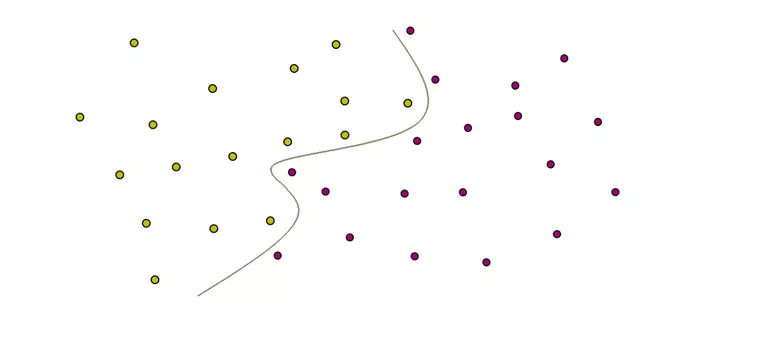
Rysunek 1.
Podział zbioru danych na grupy, bez dokonywania transformacji
Powyżej zwizualizowane jest uproszczone działanie algorytmu. Na rysunku 1. mamy sytuację wyjściową – zbiór składa się z dwóch rodzajów obserwacji, oznaczonych kolorami zielonym i fioletowym. Te dwie grupy można od siebie oddzielić, ale nie za pomocą prostego modelu liniowego, tylko poprzez krzywą. Nowe, nieznane obserwacje będą przypisywane do zielonej lub fioletowej grupy w zależności od tego, po której stronie linii się pojawią.

Rysunek 2.
Podział zbioru danych na grupy, po dokonaniu transformacji algorytmem SVM
Jak widać na rysunku 2., algorytm SVM usprawnia to zadanie, oddzielając od siebie klasy w zbiorze. Optymalna granica między nimi wyznaczona na rysunku 2. szarą linią to wspomniana hiperpłaszczyzna. Punkty leżące najbliżej hiperpłaszczyzny nazywane są wektorami nośnymi i to one odgrywają kluczową rolę w budowaniu modelu.
Zalety i wady algorytmu SVM
Do mocnych stron algorytmu SVM można zaliczyć:
- wysoką skuteczność przy małych zestawach danych – SVM dobrze radzi sobie w sytuacjach, gdy dostępnych jest stosunkowo niewiele przykładów, co czyni go idealnym dla analityków pracujących z ograniczonymi zasobami danych,
- wszechstronność – algorytm ten można stosować zarówno w prostych, jak i bardziej złożonych przypadkach, gdzie granice między grupami danych są nieregularne. SVM potrafi sobie z tym poradzić dzięki zastosowaniu odpowiednich metod matematycznych,
- odporność na przeuczenie – dzięki skupieniu na poszukiwaniu najlepszego sposobu rozdzielenia danych, SVM unika zbyt skomplikowanego dopasowywania modelu do danych.
Jednak jak każdy algorytm, SVM ma również swoje słabe strony. Podejście mocno nastawione na optymalizację jest zazwyczaj kosztowne obliczeniowo, co przy dużych zbiorach danych przekłada się na długi czas trenowania modelu. Algorytm jest też wrażliwy na przypadki odstające i anomalie w danych. Analityk musi też odpowiednio dobrać parametry do budowy modelu.
Praktyczne zastosowania SVM
Algorytm SVM znajduje zastosowanie w wielu dziedzinach, od klasyfikacji obrazów i rozpoznawania mowy, przez analizę danych medycznych, aż po segmentację klientów w marketingu. SVM może być podstawą modeli odpowiedzialnych za rozpoznawanie twarzy, analizę sentymentu czy wykrywanie spamu.
W PS CLEMENTINE PRO analitycy mogą łatwo zastosować SVM do różnego rodzaju zadań. Przedstawionym poniżej przykładem jest analiza próbek nowotworowych, gdzie dane dotyczące właściwości komórek są wprowadzane do narzędzia, a algorytm tworzy model pozwalający na precyzyjne rozróżnienie między typami próbek. Badacz może stworzyć model SVM, który wykorzysta wartości podobnych cech komórek w próbkach od innych pacjentów, aby wcześnie ocenić, czy dana próbka jest łagodna, czy złośliwa.
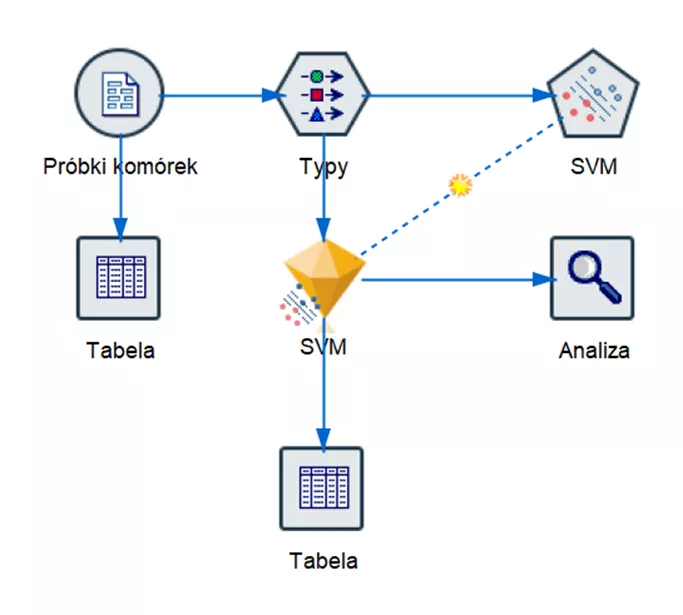
Rysunek 3.
Strumień analityczny budujący model SVM do klasyfikowania próbek nowotworowych
Podsumowanie
Algorytm SVM to skuteczne narzędzie, które pozwala analitykom skutecznie wykorzystywać dane do rozwiązywania problemów klasyfikacyjnych i regresyjnych. Jego precyzja, odporność na przeuczenie oraz wszechstronność czynią go popularnym wyborem w wielu branżach, od medycyny po marketing.
Pomimo pewnych ograniczeń, takich jak czasochłonność czy wrażliwość na anomalie, SVM pozostaje jednym z częściej wybieranych algorytmów w analizie danych. Dzięki takim narzędziom jak PS CLEMENTINE PRO, wykorzystanie SVM staje się łatwe i dostępne dla szerokiego grona użytkowników, wspierając podejmowanie trafnych i opartych na danych decyzji.