Technika ta jest często stosowana w ramach szerszej kategorii algorytmów klasyfikacyjnych, do których należą również drzewa decyzyjne, metody k-NN (k najbliższych sąsiadów), maszyny wektorów nośnych (SVM) czy sieci neuronowych.
Kluczowym aspektem analizy dyskryminacyjnej jest wykorzystanie funkcji dyskryminacyjnej do rozdzielenia grup na podstawie zmiennych i przypisania nowych obserwacji do odpowiednich kategorii.
Analiza dyskryminacyjna została po raz pierwszy opracowana przez Ronalda Fishera w 1936 roku jako metoda rozróżniania grup na podstawie wielowymiarowych danych. W kontekście uczenia maszynowego jest ona blisko związana z modelami klasyfikacyjnymi i może być stosowana jako narzędzie wspomagające tworzenie bardziej złożonych modeli.
R. Fisher zaproponował funkcję liniową, która wyraża zależność między zmiennymi niezależnymi a ich wpływem na wynik klasyfikacji, co stanowi fundament tej metody do dziś.
Wymagania analizy dyskryminacyjnej
Choć funkcja dyskryminacyjna jest zbliżona do funkcji liniowej, to założenia, które trzeba spełnić, aby można było uznać wyniki analizy za poprawne, są bardziej rozbudowane, niż w regresji liniowej.
Do najważniejszych założeń, jakie dane powinny spełniać w przypadku analizy dyskryminacyjnej, jest:
- jakościowa zmienna zależna o co najmniej dwóch kategoriach,
- ilościowe zmienne niezależne, reprezentujące próbę z wielowymiarowego rozkładu normalnego,
- jednorodność macierzy wariancji/kowariancji w grupach. Jest to istotne założenie, ponieważ naruszenia tego założenia mogą prowadzić do błędów w interpretacji wyników. Wielowymiarowy test M Boxa może być używany do sprawdzania tego założenia, ale należy go traktować ostrożnie, zwłaszcza w przypadku danych niezgodnych z normalnością,
- brak korelacji pomiędzy predyktorami. Nadmierna korelacja może prowadzić do problemów z odwracaniem macierzy wariancji/kowariancji,
- względnie równoliczne kategorie zmiennej zależnej. Duże różnice w liczebności grup mogą prowadzić do błędów klasyfikacyjnych,
- brak przypadków odstających, które mogą znacząco wpłynąć na wyniki analizy.
Pomocne w sprawdzeniu założeń oraz w wykonaniu analizy dyskryminacyjnej będzie zastosowanie PS CLEMENTINE PRO, które w łatwy sposób pozwala przeprowadzić tego rodzaju analizy. W przypadku problemów z danymi warto rozważyć transformacje (np. logarytmowanie, potęgowanie) lub zastosowanie alternatywnych metod klasyfikacji, takich jak drzewa decyzyjne, SVM czy sieci neuronowe. Są one dostępne w PS CLEMENTINE PRO.
Funkcja dyskryminacyjna
Funkcja dyskryminacyjna jest kluczowym elementem analizy dyskryminacyjnej. Pozwala na matematyczne opisanie granicy decyzyjnej pomiędzy grupami na podstawie zmiennych wejściowych. Jej ogólna postać to:
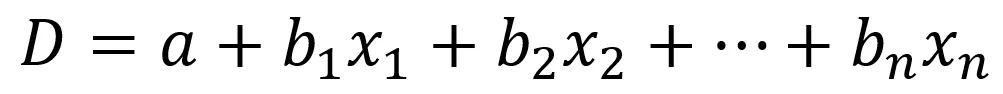
gdzie:

Funkcja ta jest wykorzystywana zarówno do tworzenia granic decyzyjnych, jak i przypisywania nowych obserwacji do odpowiednich grup.
Analiza dyskryminacyjna w PS CLEMENTINE PRO
W PS CLEMENTINE PRO analiza dyskryminacyjna jest jednym z dostępnych narzędzi analitycznych. Dzięki intuicyjnemu interfejsowi rozwiązanie umożliwia przeprowadzenie tej analizy w sposób szybki i przyjazny dla użytkownika, oferując wiele możliwości wizualizacji i interpretacji wyników.
Rysunek 1.
Przykładowy strumień analityczny wykorzystujący analizę dyskryminacyjną przygotowany w PS CLEMENTINE PRO
Analiza dyskryminacyjna, podobnie jak inne techniki klasyfikacji, pełni kluczową funkcję w procesie przypisywania obiektów do określonych grup na podstawie ich cech. Jej uniwersalność sprawia, że znajduje zastosowanie w wielu dziedzinach, takich jak finanse, nauki społeczne, marketing czy zdrowie publiczne. Przykładowo, w finansach umożliwia ocenę ryzyka kredytowego klientów, podczas gdy w marketingu wspiera segmentację klientów.
Analiza dyskryminacyjna – podsumowanie
Analiza dyskryminacyjna to zaawansowana technika statystyczna służąca do klasyfikacji obiektów na podstawie ich cech. Ważnym elementem tej metody jest funkcja dyskryminacyjna, która opisuje granice decyzyjne między grupami, umożliwiając przypisanie nowych obserwacji do odpowiednich klas. Metoda ta wymaga spełnienia szeregu założeń, takich jak wielowymiarowa normalność rozkładu zmiennych niezależnych czy brak silnej korelacji między predyktorami. Naruszenie tych założeń może prowadzić do błędów w wynikach, dlatego warto wykorzystać narzędzia takie jak PS CLEMENTINE PRO, które wspierają analizę, wizualizację i interpretację wyników.