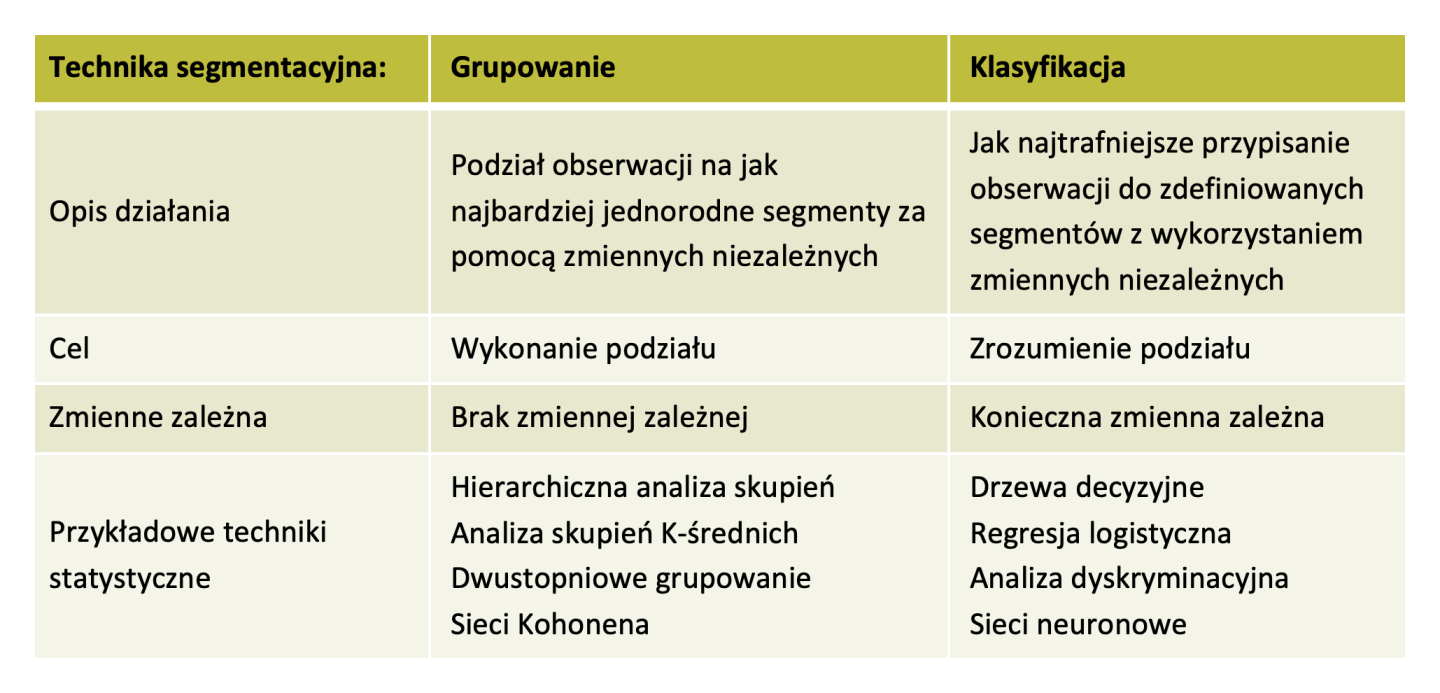
Grupowanie, inaczej też określane jako analiza skupień lub klasteryzacja (z ang. clustering), jest to proces podziału zbioru elementów na podzbiory (kategorie lub grupy) w taki sposób, aby elementy wewnątrz każdego podzbioru były bardziej podobne do siebie niż do elementów spoza tego podzbioru. Celem grupowania jest poszukiwanie naturalnych struktur lub skupisk w danych, co pozwala na identyfikację relacji między obiektami w zbiorze. Metody grupowania są szczególnie użyteczne, gdy brakuje wcześniejszego przypisania do kategorii dla analizowanych danych.
Klasyfikacja jest kolejną techniką używaną w segmentacji danych. Najczęściej w klasyfikacji mamy zbiór zmiennych w których poszczególne obserwacje są już przypisane do określonych grup docelowych. Taki zbiór stanowi wzorzec do przypisania nowej obserwacji do jednej z predefiniowanych klas. W przeciwieństwie do grupowania, klasyfikacja działa na danych, w których posiadamy zmienną zależną.
Segmentacja przyczynia się do lepszego zrozumienia danych i podejmowania trafniejszych decyzji w różnych dziedzinach, takich jak marketing, ekonomia, medycyna czy nauki społeczne.
Główne założenia dotyczące segmentacji
Założenia dotyczące segmentacji są istotne, aby cały proces był wiarygodnym narzędziem do analizy danych i podejmowania decyzji w różnych dziedzinach, takich jak marketing, zarządzanie klientami czy personalizacja usług. Dzięki spełnieniu tych założeń, segmentacja może dostarczyć wartościowych i trafnych informacji o różnych grupach. Różne techniki grupowania podchodzą w różny sposób do tworzenia segmentów, warto jednak w tym procesie zwrócić uwagę na poniżej przedstawione ogólne założenia dla segmentacji.
- Homogeniczność: Założenie to zakłada, że elementy wewnątrz każdej grupy (segmentu) są bardziej podobne do siebie niż do elementów znajdujących się w innych grupach. Innymi słowy, segmenty powinny zawierać takie obserwacje, które wykazują podobne cechy i charakterystyki.
- Różnorodność: Założenie to odnosi się do konieczności istnienia zróżnicowania między segmentami. Oznacza to, że różne grupy powinny być od siebie w istotny sposób odmienne, jeśli chodzi o określone kryteria segmentacji. W przeciwnym razie, jeśli segmenty są zbyt podobne, nie będą one dostatecznie informatywne.
- Wyłączność: To założenie zakłada, że każdy element danych musi zostać przyporządkowany do jednej z grup segmentacyjnych. Nie powinno być elementów, które pozostają bez klasyfikacji lub są przyporządkowane do więcej niż jednej grupy.
- Stabilność: To założenie sugeruje, że wyniki segmentacji powinny być stabilne i powtarzalne w różnych próbach. Oznacza to, że nawet jeśli analiza zostanie wykonana wielokrotnie na tym samym zbiorze danych, powinny powstać podobne lub identyczne grupy.
Grupowanie a klasyfikacja
Grupowanie jest często używane jako początkowy etap analizy danych, w celu identyfikacji różnych segmentów w zbiorze danych. Proces ten pozwala na zrozumienie różnic i podobieństw między różnymi obiektami w zbiorze, a także na wyodrębnienie kluczowych cech charakteryzujących każdą z grup. Jednak sam proces grupowania może dostarczyć wartościowych informacji, ale wciąż nie daje rozwiązań w konkretnych przypadkach, jakie działania powinny być podjęte wobec każdej z tych grup.
Klasyfikacja może być kontynuacją procesu grupowania i polega na przypisaniu nowych danych do istniejących wcześniej zidentyfikowanych grup. W przypadku klasyfikacji, wykorzystuje się zidentyfikowane wzorce i cechy, które wyróżniają poszczególne grupy, aby określić, do której grupy nowe obserwacje powinny zostać przypisane.
Przyjrzyjmy się przykładowej sytuacji. Prowadzimy analizę danych dotyczących klientów sklepu internetowego. Na podstawie hierarchicznej analizy skupień, zidentyfikowaliśmy trzy grupy klientów: "lojalni klienci regularnie kupujący", "okazjonalni klienci z mniejszymi zamówieniami" i "nowi klienci". Teraz, gdy nowy klient dokonuje zakupu w sklepie, wykorzystujemy model klasyfikacyjny, który bazuje na wcześniej określonych cechach (np. częstotliwość zakupów, wartość zamówień) i przypisuje tego klienta do odpowiedniej grupy. Dzięki temu mamy możliwość dostosowania oferty marketingowej, promocji czy też programów lojalnościowych dla każdej z tych grup klientów, zgodnie z ich charakterystykami i preferencjami.
Techniki grupowania
Grupowanie, zwane również analizą skupień, jest techniką analizy danych mającą na celu podzielenie zbioru obiektów na mniejsze, bardziej jednorodne grupy, w oparciu o określone kryteria podobieństwa lub bliskości. Obiekty wewnątrz każdej grupy są do siebie bardziej podobne niż do obiektów spoza tej grupy, co pozwala na wyodrębnienie znaczących struktur danych.
Do głównych algorytmów grupowania można zaliczyć:
- Algorytm k-średnich
Algorytm k-średnich jest popularnym algorytmem grupowania, który przypisuje obiekty do klastrów, minimalizując sumę kwadratów odległości każdego obiektu od środka klastra (centroidu). Algorytm rozpoczyna od wyboru początkowych centroidów, a następnie iteracyjnie przypisuje obiekty do najbliższych klastrów i aktualizuje pozycje centroidów. Proces ten trwa do momentu osiągnięcia zbieżności. Warto pamiętać o tym, że tego rodzaju technika grupowania wymaga podania liczby skupień przed rozpoczęciem analizy zbioru danych.
- Algorytmy hierarchiczne
Kolejnym popularnym algorytmem w ramach segmentacji jest grupowanie hierarchiczne, które tworzy hierarchię klastrów (grup) w formie drzewa, nazywanego dendrogramem. Algorytm rozpoczyna od pojedynczych obiektów jako osobnych klastrów i łączy je stopniowo w większe klastry na podstawie podobieństwa między nimi. W ramach tej techniki grupowania można wyróżnić dwa podejścia:- podejście aglomeracyjne, w którym to proces grupowania rozpoczyna się od utworzenia dla każdego obiektu osobnego klastra, a następnie iteracyjnie łączy się najbliższe klastry, które mają najmniejszą odległość między sobą. W każdym kroku łączenia obiektów tworzy się większy klaster, aż wszystkie obiekty zostaną połączone w jeden duży klaster lub zostanie osiągnięta określona liczba klastrów.
- podejście deglomeracyjne, które działa odwrotnie niż aglomeracyjne. Rozpoczyna się od jednego dużego klastra zawierającego wszystkie obiekty i iteracyjnie dzieli go na mniejsze klastry na podstawie odległości między obiektami. W każdym kroku podziału obiekty tworzą mniejsze klastry, aż osiągnięta zostanie określona liczba klastrów lub zostaną spełnione warunki zatrzymania.

Rysunek 1.
Przykładowy dendrogram jako wynik jednej z technik grupowania hierarchicznego.
- Algorytm grupowania gęstościowego
Algorytm grupowania gęstościowego DBSCAN (Density-Based Spatial Clustering of Applications with Noise) to technika analizy skupień, która opiera się na identyfikowaniu skupisk danych na podstawie gęstości punktów w przestrzeni. W przeciwieństwie do innych algorytmów grupowania, DBSCAN nie wymaga wcześniejszego określenia liczby klastrów, co czyni go elastycznym i łatwym w zastosowaniu. Algorytm wyróżnia punkty rdzeniowe, graniczne i szumu, co pozwala na dokładne wykrycie różnorodnych struktur danych. DBSCAN jest szczególnie użyteczny w przypadku zbiorów danych o zmiennych kształtach i gęstościach oraz potrafi skutecznie radzić sobie z punktami odstającymi.
Klasyfikacja
Klasyfikacja to sposób analizy danych, której celem jest w głównej mierze przewidywanie wartości określonej zmiennej na podstawie zbioru danych. Ogólnie celem klasyfikacji jest przypisanie danej obserwacji do z góry zdefiniowanej grupy (np. kupi – nie kupi; należy do grupy A, B lub C). Analiza polega na zbudowaniu równania, zestawu równań lub reguł, które pozwolą przypisać obserwacje z poszczególnych zmiennych do danej grupy wyznaczonej przez zmienną wyjaśnianą. W klasyfikacji zmienna wyjaśniana to właśnie przynależności do określonej grupy (segmentu). W rezultacie użycia technik klasyfikacji chcemy uzyskać odpowiedź na pytanie, jakie zmienne i jakie wartości lub zakresy wartości wpływają na przynależność do określnej grupy.
Przykładem wyniku klasyfikacji może być reguła decyzyjna dotyczące przyznania karty kredytowej: „jeżeli wiek klienta banku jest mniejszy niż 25 lub wpływy na konto bankowe są mniejsze niż 5 tys. zł , to ryzyko jest wysokie". Jeśli klient spełni jedno z kryteriów zostanie on przypisany do kategorii osób o wysokim ryzyku kredytowym.
Algorytmy klasyfikacyjne znajdują zastosowanie w wielu dziedzinach, takich jak rozpoznawanie trendów na rynkach finansowych czy wspomaganie decyzji w bankowych procesach kredytowych. W medycynie mogą być używane do klasyfikowania różnych schorzeń na podstawie danych medycznych, umożliwiając automatyczne diagnozowanie pacjentów.
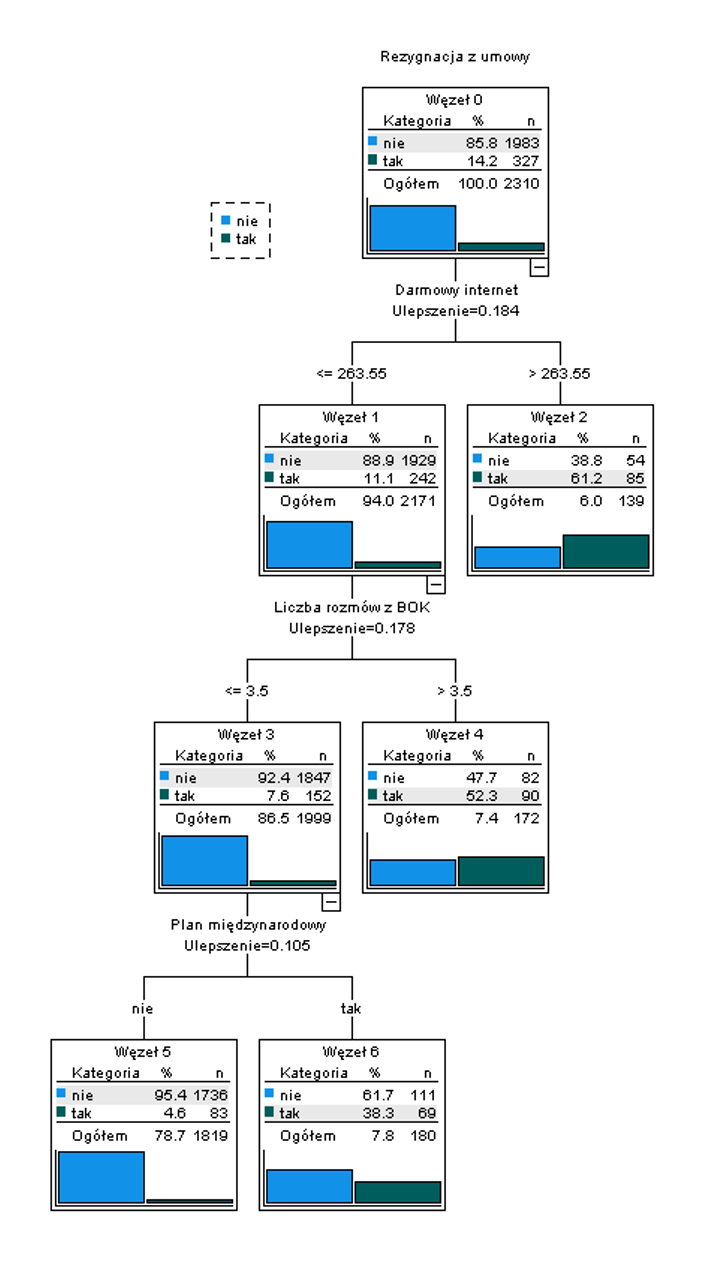
Rysunek 2.
Przykładowe drzewo decyzyjne jako wynik jednej z technik klasyfikacyjnych.
W celu przeprowadzenia klasyfikacji można wykorzystać różne techniki, między innymi analizę dyskryminacyjną, regresję logistyczną, drzewa decyzyjne oraz sieci neuronowe. Wybór odpowiedniej techniki zależy od charakterystyki danych oraz konkretnego problemu, który chcemy rozwiązać. Klasyfikacja jest kluczowym elementem wykorzystania wyników segmentacji i pozwala przekształcić zidentyfikowane grupy w konkretne i praktyczne działania biznesowe.
Podsumowanie
Segmentacja jest kluczowym procesem w analizie danych, polegającym na podziale dużego zbioru danych na mniejsze, bardziej jednorodne grupy lub segmenty na podstawie określonych kryteriów. Celem segmentacji jest identyfikacja ukrytych wzorców, różnic i podobieństw między obiektami w zbiorze danych, co umożliwia bardziej precyzyjne i trafne analizy. Analiza skupień i klasyfikacja stanowią kluczowe narzędzia w analizie danych, pozwalając na lepsze zrozumienie danych, identyfikację relacji i podejmowanie trafniejszych decyzji w różnych dziedzinach, takich jak marketing, ekonomia, medycyna czy nauki społeczne.