
5 najbardziej użytecznych wykresów w PS IMAGO PRO cz. 2
W kolejnym materiale z serii o ciekawych i użytecznych wizualizacjach w PS IMAGO PRO przyglądamy się wykresom, które pojawiają się rzadziej niż klasyczne słupki czy linie, ale w wielu sytuacjach okazują się znacznie bardziej użyteczne.
Przeczytaj więcej
5 najbardziej użytecznych wykresów w PS IMAGO PRO cz. 1
W analizie danych ilościowych najczęstszym problemem jest właściwe przedstawienie informacji – tak, aby odbiorca był w stanie szybko zrozumieć, co z danych wynika i dlaczego ma to znaczenie.
Przeczytaj więcej
Jak wybrać oprogramowanie do analizy danych?
O tym, czy wybór narzędzia analitycznego jest dobry, rzadko możemy być pewni na etapie demo. Prawdziwy test zaczyna się później: kiedy trzeba podłączyć dane z kilku źródeł, zrobić porządek w definicjach, odświeżać wyniki co tydzień i jeszcze wytłumaczyć je biznesowi tak, żeby ktoś na tej podstawie …
Przeczytaj więcej
Segmentacja własnych klientów – jak zrobić ją automatycznie?
Segmentacja klientów to temat, który większość firm ma już przynajmniej oswojony. Najczęściej zaczyna się od prostego podziału bazy: według wartości zakupów, wieku, branży, regionu czy częstotliwości kontaktu.
Przeczytaj więcej
Skale pomiarowe w badaniach ankietowych – najczęstsze błędy i jak ich uniknąć
Skala w badaniach ankietowych to narzędzie, które decyduje o tym, jakie informacje uda się zebrać i jak je później zinterpretować. W praktyce wiele błędów pojawia się już na etapie projektowania narzędzia badawczego: nieprecyzyjne pytania, źle dobrana forma odpowiedzi, podejście do wielowymiarowego…
Przeczytaj więcej
Jak przygotować dobry raport? Zestaw dobrych praktyk analityka
W każdej organizacji regularnie powstają raporty: sprzedażowe, finansowe, HR-owe, operacyjne. Część z nich realnie wpływa na decyzje, część po prostu krąży w obiegu – otwierane „na szybko”, przeglądane wybiórczo, odkładane na później. Różnica między jednymi a drugimi nie leży jednak w samym formaci…
Przeczytaj więcej
Modele predykcyjne: jak zwiększyć ich skuteczność?
W wielu firmach modele predykcyjne przestają być ciekawostką z działu analiz i stają się elementem codziennego zarządzania, gdzie przewidujemy odejścia klientów, ryzyko opóźnień płatności, popyt, awarie, czy nadużycia. Metryki mogą wyglądać dobrze, testy przechodzić pomyślnie, a mimo tego po kilku …
Przeczytaj więcej
Skale w badaniach ankietowych. Jak dobrać odpowiednią skalę?
Badania ankietowe stawiają przed badaczami szczególne wyzwania. W przeciwieństwie do nauk przyrodniczych, w badaniach społecznych przedmiotem pomiaru są często zjawiska abstrakcyjne, takie jak zaufanie społeczne, satysfakcja czy postawy wobec instytucji. Zjawisk tych nie da się zmierzyć bezpośredni…
Przeczytaj więcej
Dashboard vs. raport – co lepiej wspiera decyzje zarządu?
W wielu organizacjach liczba dostępnych danych rośnie szybciej niż czas, który menedżerowie mogą poświęcić na ich analizę. Jedni proszą o kolejne raporty, inni oczekują nowoczesnych dashboardów. Pytanie, które coraz częściej pada w działach biznesowych i analitycznych, brzmi: co lepsze do raportowa…
Przeczytaj więcej
Integracja PS IMAGO PRO i R. Praktyczny przykład z użyciem diagramu Venna
Analiza danych to nie tylko wyliczanie podstawowych statystyk, ale przede wszystkim eksploracja i interpretacja wyników analiz, które pomagają podejmować trafne decyzje biznesowe.
Przeczytaj więcej
Python w PS CLEMENTINE PRO – najważniejsze możliwości
Przez lata SPSS Clementine było uważane za wzorzec środowiska otwartego wśród systemów eksploracyjnej analizy danych.
Przeczytaj więcej
PS IMAGO PRO i PS CLEMENTINE PRO – jak zintegrować klasyczne podejście analiz statystycznych z data science
W codziennej pracy analitycznej często łączymy różne rozwiązania, bo każde z nich pozwala realizować inny fragment procesu. Jedno narzędzie przydaje się do pobierania i przetwarzania danych, drugie do budowania skomplikowanych modeli, a trzecie do szczegółowych analiz statystycznych.
Przeczytaj więcej
O trzech sposobach rozumienia rzetelności w badaniach ankietowych
Nieodzownym zagadnieniem, związanym z badaniami sondażowymi, jest rzetelność narzędzi badawczych. Przed przystąpieniem do projektowania badania społecznego lub marketingowego z wykorzystaniem kwestionariusza ankiety, należy zastanowić się nad rzetelnością pytań.
Przeczytaj więcej
Przegląd klasycznych modeli rzetelności – część 2
Z poprzedniej części znasz już znaczenie rzetelności w analizach danych ankietowych oraz model alfa Cronbacha. Dowiesz się z niej także, w jaki sposób interpretować wartość tego współczynnika i jak wpływa na nią zarówno liczba pozycji skali, jak i siła korelacji między nimi.
Przeczytaj więcej
Przegląd klasycznych modeli rzetelności – część 1
Rzetelność skali pomiarowej to jeden z najważniejszych elementów każdej analizy danych ankietowych, szczególnie w badaniach społecznych, psychologicznych czy marketingowych. To właśnie dzięki niej możemy ocenić, na ile nasze narzędzie badawcze mierzy w sposób stabilny i spójny to, co zamierzamy bad…
Przeczytaj więcej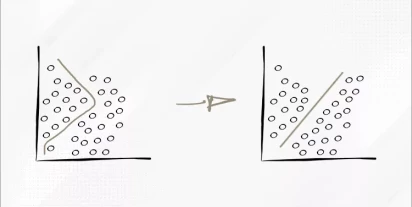
Algorytm SVM – co to jest i jak go wykorzystać w praktyce?
W dzisiejszym świecie pełnym danych analitycy często mierzą się z wyzwaniem, jak skutecznie wydobyć z nich wartościowe informacje.
Przeczytaj więcej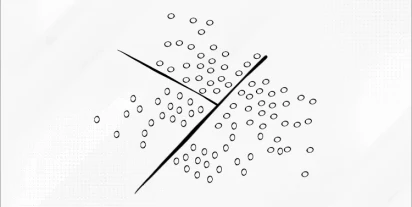
Analiza dyskryminacyjna
Analiza dyskryminacyjna jest jedną z technik statystycznych wykorzystywanych do klasyfikacji obiektów na podstawie ich cech.
Przeczytaj więcej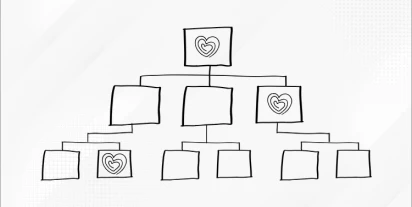
Drzewa decyzyjne i ich udoskonalenia: od podstaw po zaawansowane techniki
Drzewo decyzyjne to popularny i skuteczny algorytm, wykorzystywany szczególnie w zadaniach klasyfikacyjnych, ale dobrze sprawdza się również w przypadku przewidywania zjawisk ilościowych. Jego atrakcyjność wynika m.in. z faktu, że reprezentuje zestaw prostych reguł decyzyjnych, które można zapisać …
Przeczytaj więcej
Diagram zadania – nowe możliwości tworzenia i wizualizacji procesów w PS CLEMENTINE PRO
Tworzenie i zarządzanie zadaniami analitycznymi to ważna część pracy z narzędziami typu ETL (ang. Extract, Transform and Load, czyli wyodrębnianie, przekształcanie i ładowanie) oraz programami do zaawansowanej analizy danych.
Przeczytaj więcej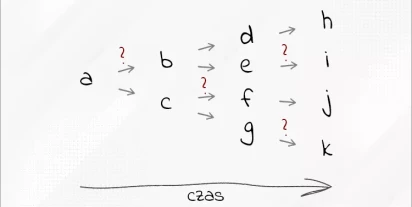
Indukcja reguł sekwencyjnych
Indukcja reguł sekwencyjnych to zaawansowana technika eksploracji danych, która umożliwia odkrywanie wzorców występujących w sekwencjach zdarzeń.
Przeczytaj więcej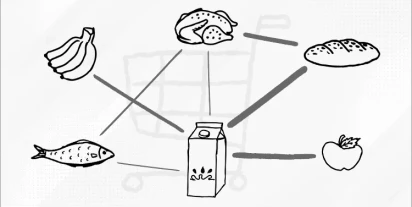
Analiza koszykowa: Zastosowanie i charakterystyka
Analiza koszykowa to popularna technika eksploracji danych, wykorzystywana przede wszystkim pod kątem zawartości koszyków zakupowych w handlu detalicznym, marketingu oraz e-commerce.
Przeczytaj więcej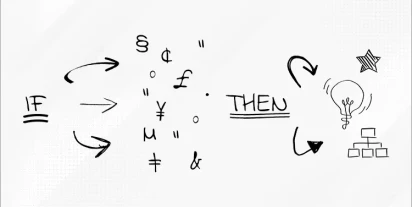
Algorytmy indukcji reguł – odkrywanie wzorców w danych
Indukcja reguł jest jedną z kluczowych metod w dziedzinie sztucznej inteligencji i uczenia maszynowego. Umożliwia automatyczne wyodrębnianie wzorców i zależności z danych. Ta technika polega na analizie zbiorów danych w celu sformułowania ogólnych reguł, które opisują relacje pomiędzy zmiennymi w z…
Przeczytaj więcej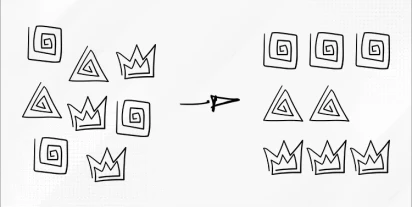
Auto Klasyfikacja – automatyczny wybór modelu do danych w PS CLEMENTINE PRO
Podczas pracy z danymi analityk często staje przed wyzwaniem wyboru odpowiednich testów statystycznych, które pozwolą uzyskać wartościowe odpowiedzi na postawione pytania badawcze. Rozwiązaniem tego problemu może być PS CLEMENTINE PRO. Narzędzie to oferuje szeroką gamę metod modelowania, które opie…
Przeczytaj więcej
Automatyczne przygotowywanie danych do analizy, cz. II
Przygotowanie danych do analizy, jak już wielokrotnie było powtarzane na tym blogu, jest kluczowym elementem analizy. Często jest to proces czasochłonny oraz trudny, który nawet doświadczonym analitykom danych może sprawiać problemy. W tym artykule wracamy do kwestii automatycznego przygotowania d…
Przeczytaj więcej
Automatyczne przygotowywanie danych do analizy
Przygotowanie danych odgrywa kluczową rolę w analizie danych i procesach uczenia maszynowego. Jego znaczenie wynika z kilku ważnych aspektów, które wpływają na jakość i wiarygodność wyników. Dane o wysokiej jakości mają wpływ na dokładniejsze i bardziej wiarygodne modele statystyczne. Surowe, niepr…
Przeczytaj więcej
Współczynnik determinacji R²: co to jest i jak go interpretować?
Współczynnik determinacji, oznaczany jako R² (R-kwadrat), jest jednym z najczęściej używanych narzędzi statystycznych do oceny modelu. Oferuje on miarę tego, jak dobrze testowany model dopasowuje się do danych. W tym artykule przyjrzymy się, czym dokładnie jest współczynnik R² i jaką rolę odgrywa w…
Przeczytaj więcej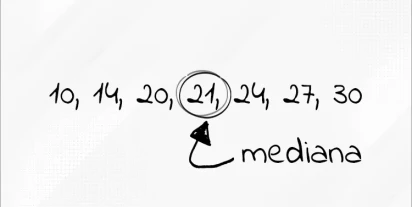
Mediana
Mediana jest statystyką, którą zaliczamy do miar tendencji centralnych. Jest jedną z najpopularniejszych statystyk opisowych obok średniej arytmetycznej. Dla młodych adeptów sztuki analitycznej jest to statystyka, z którą zapoznają się jako jedną z pierwszych. Warto dodać, że oprócz prostej interpr…
Przeczytaj więcej
Predykcyjne AI vs generatywne AI – charakterystyka, różnice
Sztuczna inteligencja (ang. artificial intelligence, AI) to jedno z najbardziej ekscytujących i dynamicznie rozwijających się obszarów technologii współczesnego świata. Od samouczących się algorytmów, przez zaawansowane systemy rozpoznawania obrazów, aż po autonomiczne pojazdy – AI rewolucjonizuje …
Przeczytaj więcej
Wykres kołowy
Nie wiem czy wiecie, ale w 2021 roku „poczciwy” wykres kołowy obchodził 220. urodziny. Przez te lata stał się jednym z najbardziej rozpoznawalnych narzędzi w analizie danych. Wykorzystywany jest w różnych dziedzinach, od marketingu po nauki przyrodnicze, pomagając w prosty sposób przedstawiać skomp…
Przeczytaj więcej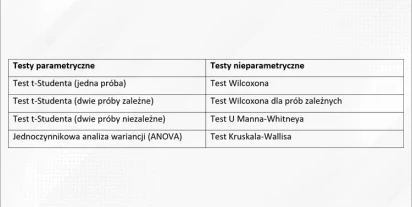
Testy parametryczne a nieparametryczne. Jaki test wybrać do analizy?
Analiza statystyczna jest nieodłącznym elementem badań naukowych i pracy z danymi. Aby wyciągnąć prawidłowe wnioski, niezbędne jest zastosowanie odpowiednich testów statystycznych. Analityk często staje przed wyborem, który test w danej sytuacji wybrać. Jest to ważne, ponieważ niewłaściwe dobranie …
Przeczytaj więcej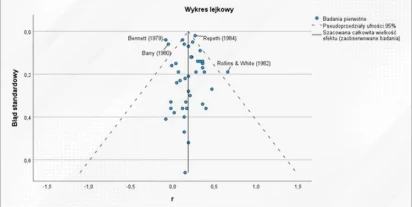
Metaanaliza jako narzędzie analityczne
W dzisiejszym świecie naukowym i badawczym analitycy często napotykają problem analizy dużych ilości danych, pochodzących z różnych badań. W takich sytuacjach metaanaliza staje się niezastąpionym narzędziem. Umożliwia zbiorczą ocenę wyników wielu badań i wyciąganie bardziej precyzyjnych wniosków. W…
Przeczytaj więcej
Ogólne modele liniowe i uogólnione modele liniowe - różnice oraz podobieństwa
W analizie danych, stosowanie ogólnych modeli liniowych jest powszechne ze względu na ich prostotę i łatwość w interpretacji uzyskanych wyników. Jednakże zdarza się, że analityk napotyka sytuacje, w których założenia klasycznych modeli liniowych są trudne lub niemożliwe do spełnienia. Może to wynik…
Przeczytaj więcej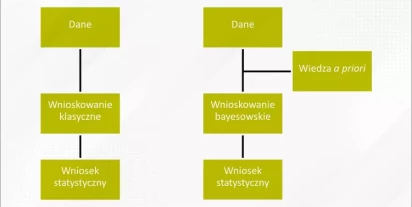
Wnioskowanie bayesowskie
Wnioskowanie bayesowskie to metoda wnioskowania statystycznego. Została tak nazwana na cześć Thomasa Bayesa, brytyjskiego matematyka i pastora, który po raz pierwszy sformułował teorię prawdopodobieństwa bayesowskiego w XVIII wieku. To metoda analizy danych, która pozwala na określenie prawdopodobi…
Przeczytaj więcej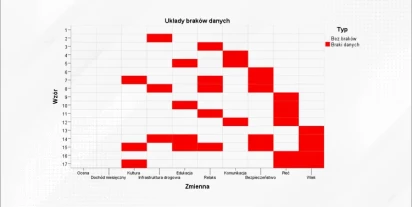
Braki danych w ilościowej analizie danych – czym są i jak sobie z nimi radzić?
Braki w kontekście analizy danych oznaczają sytuacje, gdy w zbiorze danych nie ma wartości dla niektórych zmiennych lub obserwacji. Innymi słowy, są to miejsca, w których oczekiwano liczby, tekstu, czy innej formy danych, ale z różnych przyczyn się tam nie znalazły. Braki danych mogą mieć różne for…
Przeczytaj więcej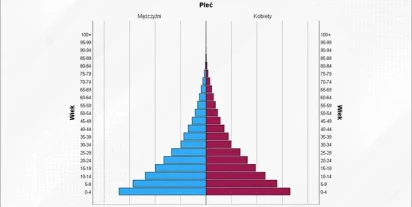
Piramida populacyjna
Poszukując najlepszej metody wizualizacji posiadanych danych, natrafić można na imponująco szeroką paletę różnego rodzaju wykresów – od prostych, podstawowych takich jak wykres rozrzutu, do bardzo zaawansowanych jak diagram Sankeya. Niektóre z nich zostały jednak stworzone z myślą o specyficznym ro…
Przeczytaj więcej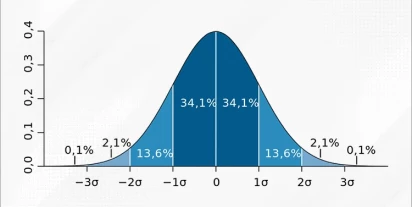
Reguła trzech sigm
Reguła trzech sigm jest ważnym narzędziem w statystyce i zarządzaniu jakością. W kontekście analizy danych, pozwala na identyfikację punktów odstających, które znacznie różnią się od reszty danych. Wykorzystanie reguły trzech sigm w kontroli jakości pozwala również na ujawnienie anomalii, co umożli…
Przeczytaj więcejZainteresowaliśmy Cię?
Chętnie porozmawiamy na tematy dotyczące zastosowania analizy danych w twoich działaniach.
Dysponujemy wiedzą z wielu obszarów i znamy specyfikę branż.
